这篇我们讲讲 Actor-Critic 的两个进阶版本 A2C 和 A3C。
Advantage Actor-Critic
基础的 Actor-Critic 中,Critic 输出Q value 用于策略梯度的计算。但这种方式也有跟 policy gradient 中类似的问题,就是High variance。为了解决这个高方差的问题,可以采用引入一个baseline的方式,即在计算期望的时候用累计奖励减去一个 Baseline ,这样做的好处是可以让梯度减小,因此梯度下降的步子也就更平缓,从而使训练过程更稳定 。
\nabla_{\theta} J(\theta) = E_{\tau} [\sum_{t=0}^{T} \nabla log \pi_{\theta}(a_t|s_t)(G_t-b(S_t))]
本着这种思想,可以对前面的 Q Actor-Critic 算法做改进,如果让Q(s_t,a_t)减去一个 baseline 的话,最理想也是最自然的选择的就 V(s_t)了,这样就可以构造出优势函数 Advantage function:
A(s_t,a_t) = Q(s_t,a_t)-V(S_t)
因此原先用 Critic 网络对 Q 值的估计就可以改成对优势函数的估计,估算每个 imath[/imath] 对相对于平均值 V(s_t)的优势。这种算法就是 Advantage Actor Critic ,即 A2C。
A2C 在具体实现的时候,不需要让Critic网络同时输出 Q 值和 V 值,只需要输出 V 就够了,而 Advantage 可以根据近似计算得到:

核心设计 — 并行架构
深度强化学习中,大部分基础算法都是单线程的,也就是一个 agent 去跟环境交互产生经验。包括前面的基础版 Actor-Critic ,由于环境是固定不变的,agent 的动作又是连续的,这样收集到的经验就有很强的时序关联,而且在有限的时间内也只能探索到部分状态和动作空间。
为了打破经验之间的耦合,可以采用Experiencre Replay的方法,让 agent 能够在后续的训练中访问到以前的历史经验,这就是 DQN 和 DDPG 这类基于值的(DDPG虽然也属于 Actor-Critic 架构,但本质上是 DQN 在连续空间中的扩展)算法所采用的方式。而对于基于策略类的算法,agent 收集的经验都是以 episode为单位的,跑完一个episode 后经验就要丢掉,更好的方式是采用多线程的并行架构,这样既能解决前面的问题,又能高效利用计算资源,提升训练效率。
A2C 和 A3C 这两种算法,创新的引入了并行架构,即整个agent 由一个 Global Network 和多个并行独立的 worker 构成,每个 worker 都包括一套 Actor-Critic 网络。而各个 worker 都会独立的跟自己的环境去交互,得到独立的采样经验,而这些经验之间也是相互独立的,这样就打破了经验之间的耦合,起到跟 Experiencre Replay 相当的效果。因此通常 A2C和A3C 是不需要使用 Replay Buffer 的,这种结构本身就可以替代了。

并行架构的优势:
打破经验之间的耦合,起到类似于经验回放的作用,但又避免了 Repaly Buffer 内存占用过大的问题
多个 worker 独立探索一个环境的副本,相当于同时去探索环境的不同部分,并且使用不同的策略也可以极大提升多样性(只限于 A3C),充分发挥探索的优势
充分利用计算资源,可以在多核 CPU 上实现与 GPU 训练像媲美的效果;
有效缩短训练时间,训练时间与并行进程的数量呈现近似线性的关系;
由于舍弃了Repaly Buffer,就可以使用 on policy 类的算法,而不用局限于 off policy (如q learning)
在这种并行架构下,同一个episode中,每个 agent 都会采样得到不同的经验,就会计算出不同的梯度。如何处理这些不同的梯度,以及如何把多个 agent 的参数整合到统一的 Global Network 中,就可以有同步和异步两种不同的方式,因此衍生出了两种不同的算法。
异步和同步
A3C 是最早出现的版本,采用异步梯度更新的方式,不同的 worker 获取独立的经验后(一个 batch),独立的去更新 Global Network,当主网络参数被更新了以后,就用最新的参数去重置所有的 worker,然后在开始下一轮循环。
具体来说,就是每个 worker 会根据当前获取的一轮经验去计算各自的损失函数,得到各自独立的梯度以后,把这个梯度上传到 Global Network 中,而 Global Network 再分别根据接收到的梯度进行梯度下降更新参数,并用最新的参数去更新对应的 worker。
A3C 异步更新的问题曾经困扰了我很久,一直纠结于各个 woker 更新的时机,还有他们究竟是如何跟 Global 取得同步的。(这个地方网上很多资料解释的并不是很清楚,有些模棱两可),翻遍了各种博文和原论文也没找到答案,后来我决定自己撸一遍代码,终于把思路理清了,于是画了个流程图,希望能把这个过程解释清楚。
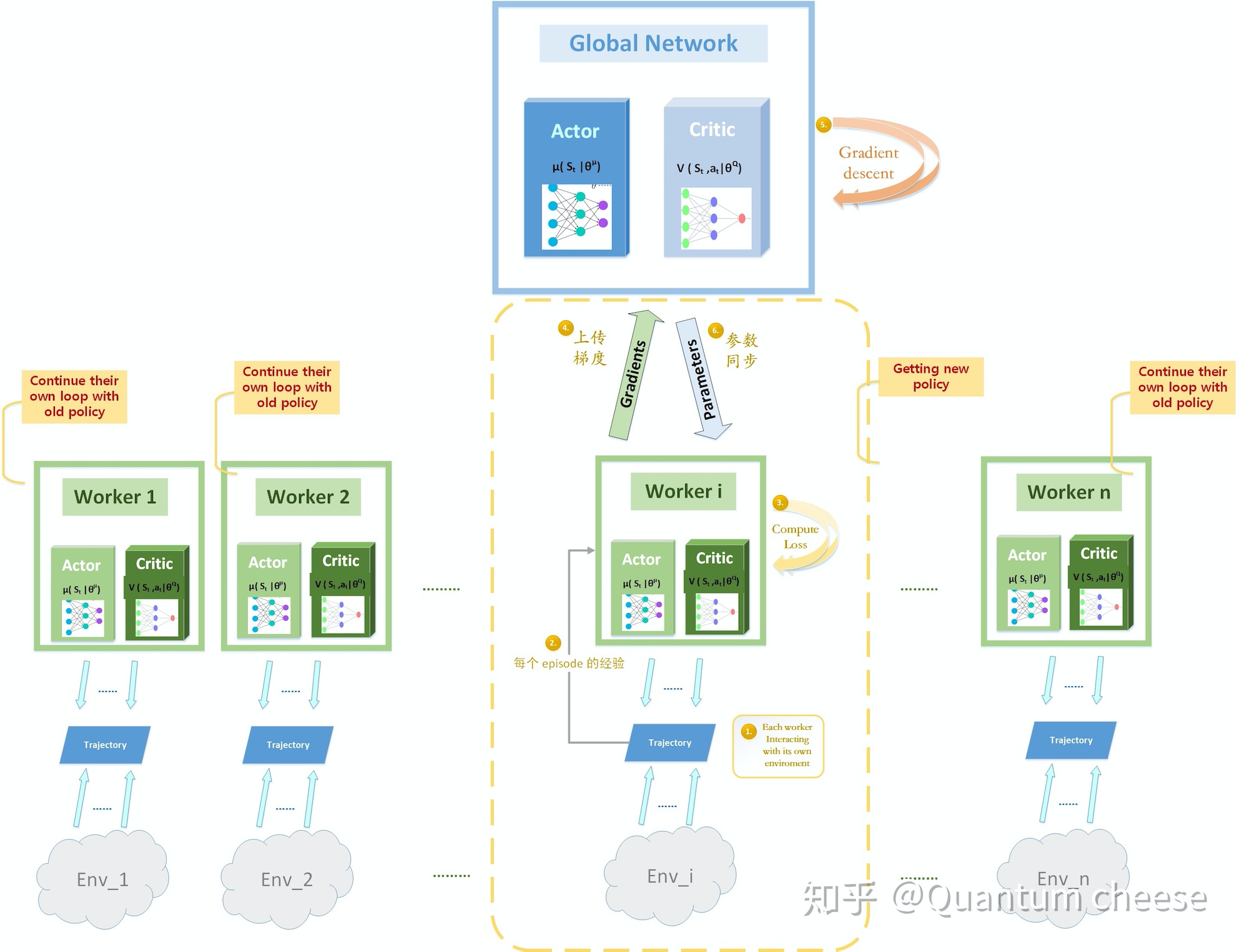
上图表示的是在某一时刻,其中一个 worker i 跑完了它当前的循环(完成一个episode),于是它就用这个 tajectory的经验计算 actor loss 和 critic loss,计算梯度并上传给 global network,而 lobal network 进行梯度下降后得到新的参数,再传回给那个 woker i ,这时主网络和 worker i 的参数同时得到更新;而与此同时,其它的woker 还在跑它们自己的循环,完全不受影响,当 worker i 开始新循环以后,它跟其它 worker 使用的都是不同的 policy。直到某个 worker 跑完了自己的循环,再次重复以上过程。
总结一下异步更新的关键点:
每个 worker 就是一个并行的独立进程,当某个 worker_i 当前 episode 并利用独立的经验计算出相应的损失函数后,会把梯度传递给 Global network,然后 Global network 进行梯度下降更新参数,并把最新的网络参数传递回对应的那个 worker_i ,这样 worker_i 就跟主网络同步了;
当 worker_i 跟主网络同步后,它会使用更新后的策略与环境交互。但此时其它进程中的 workers 并没有跟主网络同步,它们还是使用上次更新后的策略在运行,直到跑完当前 episode 才能跟主网络同步;
这意味在特定时刻,每个 worker 都不是同步的,很有可能各个 worker 都分别使用着一套不同的策略 ,独立的跟自己的环境交互。而主网络保持着最新的策略,各 worker 跟主网络同步的时间也是不一样的,只要有一个 worker 完成当前episode,主网络就会根据它的梯度进行更新,并不影响其它仍旧在使用旧策略的 worker。这就是异步并行的核心思想。
(搞清楚了这些,A3C就不再神秘,我用pytorch和python的multiprocessing 实现了A3C,并在 openai 的 gym 小项目上练了练手,相关实现代码看这里 https://github.com/Quantum-Cheese/DeepReinforcementLearning_Pytorch/tree/master/Actor_Critic)
A2C — 同步更新
A2C 是 A3C 的同步版本。
A2C 也会构建多个进程,包括多个并行的 worker,与独立的环境进行交互,收集独立的经验。
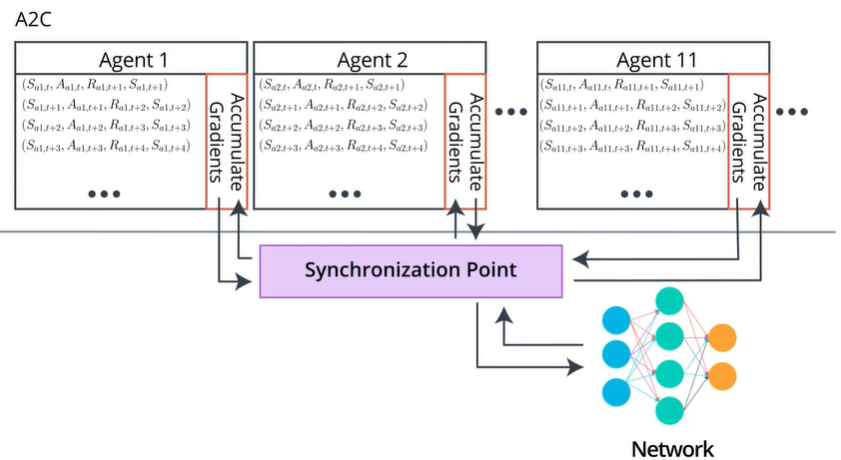
但是这些 worker 是同步的,即每轮训练中,Global network 都会等待每个 worker 各自完成当前的 episode,然后把这些 worker 上传的梯度进行汇总并求平均,得到一个统一的梯度并用其更新主网络的参数,最后用这个参数同时更新所有的 worker。 相当于在 A3C 基础上加入了一个同步的环节。
A2C 跟 A3C 的一个显著区别就是,在任何时刻,不同 worker 使用的其实是同一套策略,它们是完全同步的,更新的时机也是同步的。由于各 worker彼此相同,其实 A2C 就相当于只有两个网络,其中一个 Global network 负责参数更新,另一个负责跟环境交互收集经验,只不过它利用了并行的多个环境,可以收集到去耦合的多组独立经验。
A2C 和 A3C 的区别用下面的图就可以清晰说明了,A2C 比 A3C 多的就是一个中间过程,一个同步的控制,等所有 worker 都跑完再一起同步,用的是平均梯度或累加梯度。因此这些worker们每时每刻使用的都是同样的策略,而 A3C 中不同的 worker 使用的策略可能都不相同。
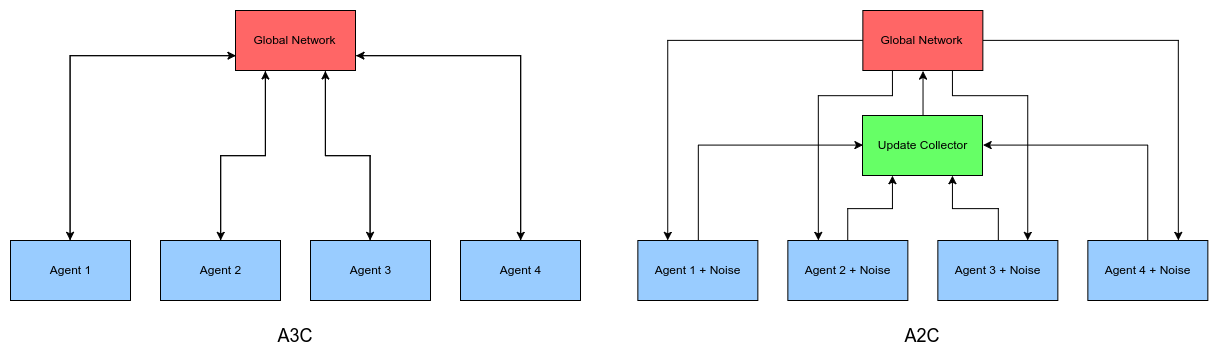
相比于A3C,A2C有一些显著的优势:
- A3C 中各个 agent 都是异步独立更新,每个 agent 使用不同的策略,可能会导致 global policy 的累计更新效果并不是最优(optimal)的。而 A2C 通过同步更新解决了这种不一致( inconsistency)的问题;
- A2C 的同步更新会让训练更加协调一致,从而潜在的加快收敛;
- 经过实践证明,A2C 对 GPU 的利用率更高,对于大 batch size 效果更好,而且在相同任务中比 A3C 取得更好的性能。