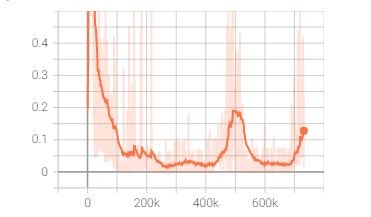
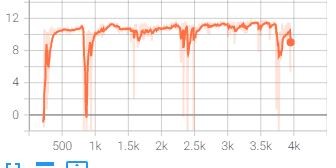
请问大家有没有遇到过,训练过程中Q网络损失收敛一段时间后突然又变大然后又逐渐收敛,但同时奖励值并没有明显提升,反而下降的现象。这导致我的训练曲线总感觉收敛性不佳。请问是我的网络结构太简单还是学习率太大了?@实验室官方助手 Loss和Reward图如下。
我也在使用TD3,发现reward值不收敛,不知道是因为什么
我在使用TD3做虚拟机动态迁移策略时,使用自己写的Env,也遇到了类似问题。不过具体是ActorNet训练几百步后出现一直选择边界动作问题(比如action space为[0,5],则始终选择0或5),很可能是激活函数sigmoid或tanh的饱和区导致的,不过目前还没想到解决办法