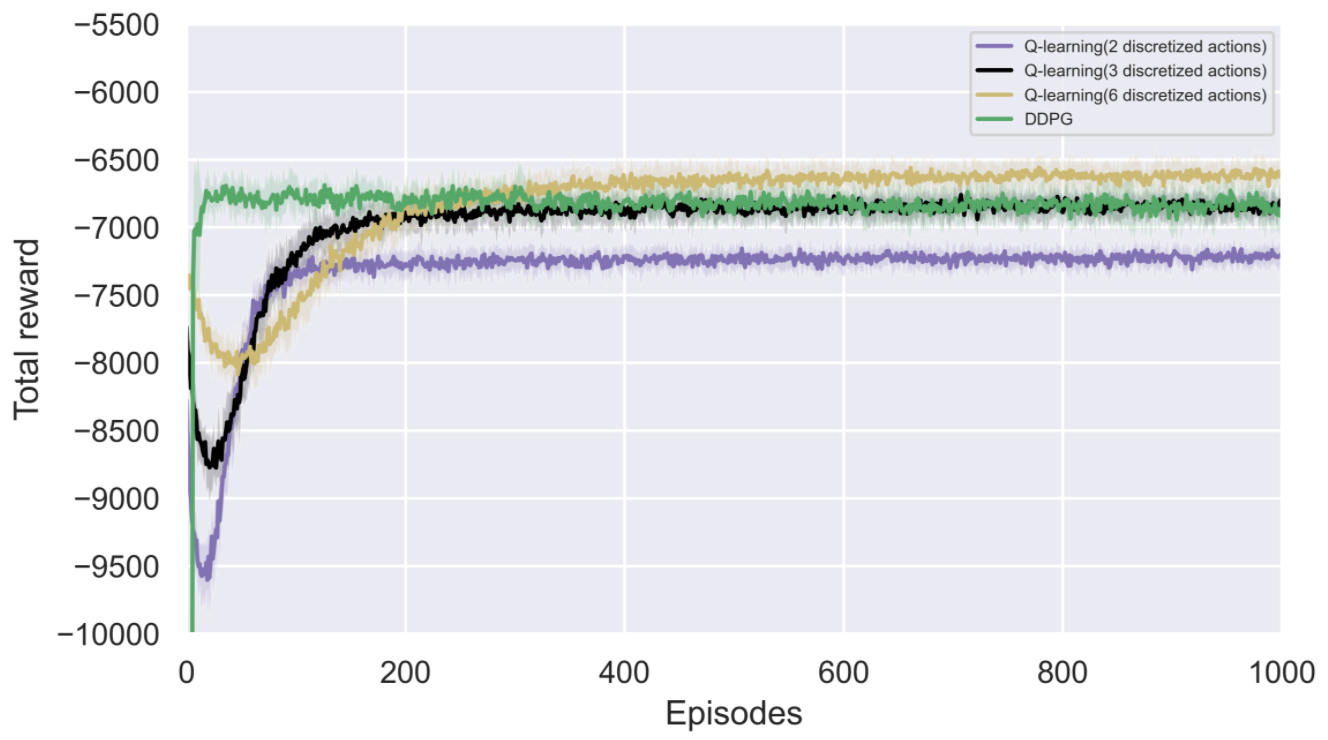
如图,Q-learning离散化的action多了之后,效果比DDPG还好,请问这是什么原因呢? action是[0,1]连续的值,Q-learning离散化6个action为{0,0.2,0.4,0.6,0.8,1}
ddpg本身的性能就不怎么好吧,试一下ppo或sac呢
图中显示DDPG的收敛性能已经吊打Ql了,感觉可能是参数设置没有让DDPG发挥出全部实力
离散化粒度只有6,Q-learning的探索效率远高于DDPG。 这说明在你的任务中,探索效率提升带来的收益超过了控制精度下降带来的损失。 如果离散化再精细一些,可能还会继续提升性能,直到上述收益与损失的关系发生逆转。 本来连续动作空间在探索效率上就是吃亏的,DDPG叠加噪声的方式有很大改进空间,比如parameter noise等等。
我想问,怎么把三种结果显示在一张图上的?是三个程序一起跑,结果绘图在一起吗
叶天天 首先,依次运行算法,并将运行结果保存到文件中;最后,通过读取文件数据,绘制图表。