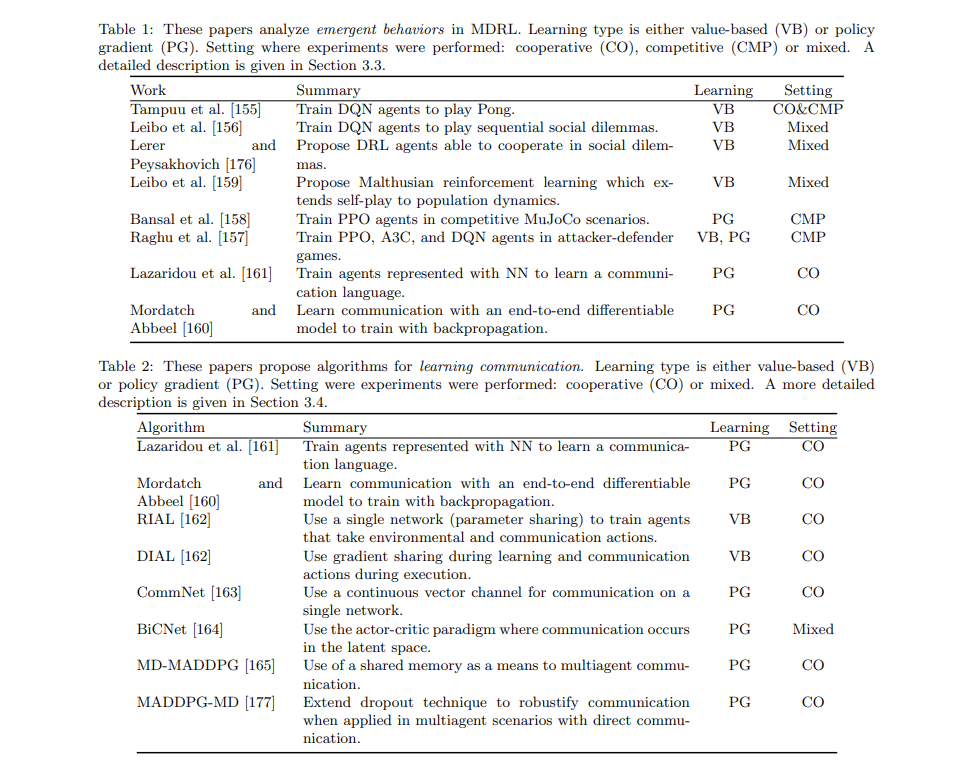
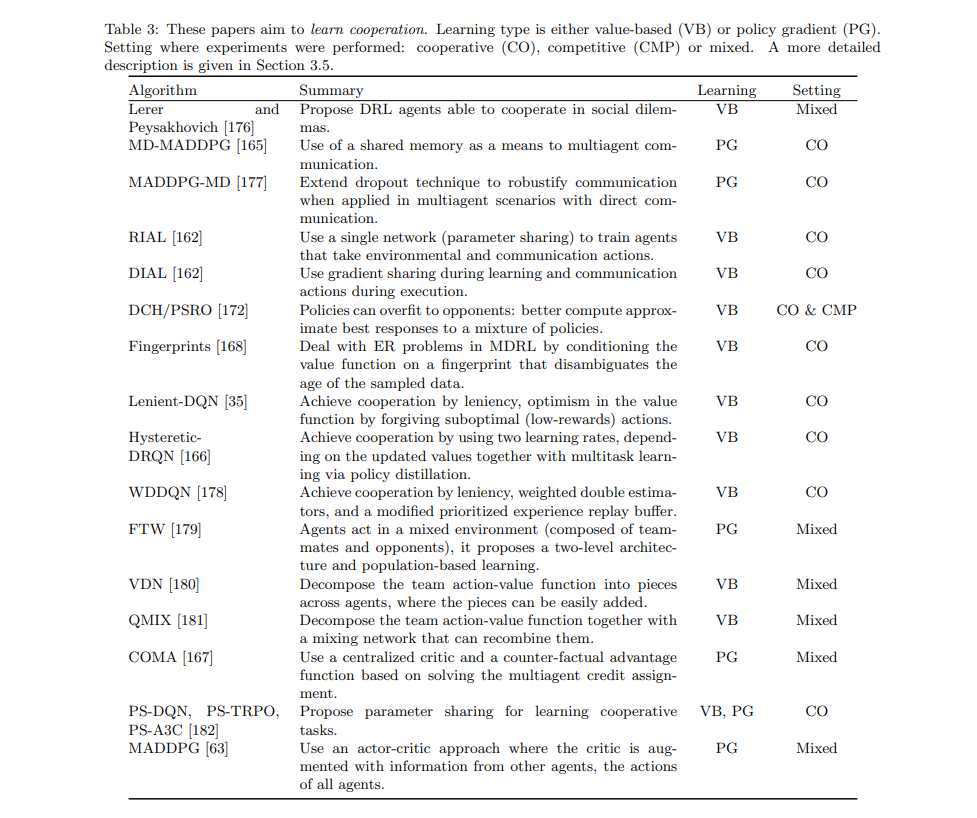
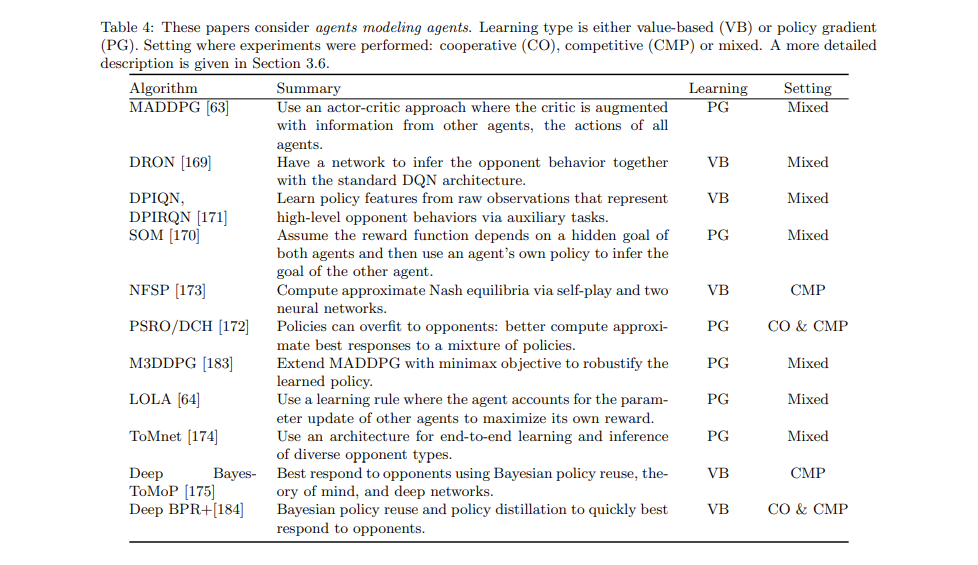
Arxiv: https://arxiv.org/pdf/1810.05587.pdf
深度强化学习(RL)近年来取得了突出的成果,这导致应用程序和方法的数量急剧增加。最近的工作探索了超越单智能体场景的学习,并考虑了多智能体学习 (MAL) 场景,在复杂的多智能体领域取得了成功。本文的主要目标是提供对当前多智能体深度强化学习 (MDRL) 文献的清晰概述。此外,我们通过更广泛的分析补充了概述:
- (i)我们重新审视了最初出现在 MAL 和 RL 中的以前的关键组件,并强调了它们是如何适应多智能体深度强化学习设置的。
- (ii) 我们为该领域的新从业者提供一般指南:描述从 MDRL 工作中吸取的经验教训,指出最近的基准,并概述开放的研究途径。
- (iii) 我们采取更批判的语气提出 MDRL 的实际挑战(例如,实施和计算需求)。
我们希望本文将有助于统一和激励未来的研究,以利用现有的丰富文献(例如 RL 和 MAL)共同努力促进多智能体社区的富有成效的研究。