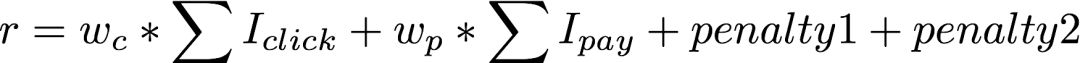1. 概述
“猜你喜欢”是美团流量最大的推荐展位,位于首页最下方,产品形态为信息流,承担了帮助用户完成意图转化、发现兴趣、并向美团点评各个业务方导流的责任。经过多年迭代,目前“猜你喜欢”基线策略的排序模型是业界领先的流式更新的Wide&Deep模型[1]。考虑Point-Wise模型缺少对候选集Item之间的相关性刻画,产品体验中也存在对用户意图捕捉不充分的问题,从模型、特征入手,更深入地理解时间,仍有推荐体验和效果的提升空间。近年来,强化学习在游戏、控制等领域取得了令人瞩目的成果,我们尝试利用强化学习针对以上问题进行优化,优化目标是在推荐系统与用户的多轮交互过程中的长期收益。
在过去的工作中,我们从基本的Q-Learning着手,沿着状态从低维到高维,动作从离散到连续,更新方式从离线到实时的路径进行了一些技术尝试。本文将介绍美团“猜你喜欢”展位应用强化学习的算法和工程经验。第2节介绍基于多轮交互的MDP建模,这部分和业务场景强相关,我们在用户意图建模的部分做了较多工作,初步奠定了强化学习取得正向收益的基础。第3节介绍网络结构上的优化,针对强化学习训练不稳定、难以收敛、学习效率低、要求海量训练数据的问题,我们结合线上A/B Test的线上场景改进了DDPG模型,取得了稳定的正向收益。第4节介绍轻量级实时DRL框架的工作,其中针对TensorFlow对Online Learning支持不够好和TF Serving更新模型时平响骤升的问题做了一些优化。

2. MDP建模
在“猜你喜欢“展位中,用户可以通过翻页来实现与推荐系统的多轮交互,此过程中推荐系统能够感知用户的实时行为,从而更加理解用户,在接下来的交互中提供更好的体验。“猜你喜欢”用户-翻页次数的分布是一个长尾的分布,在下图中我们把用户数取了对数。可知多轮交互确实天然存在于推荐场景中。
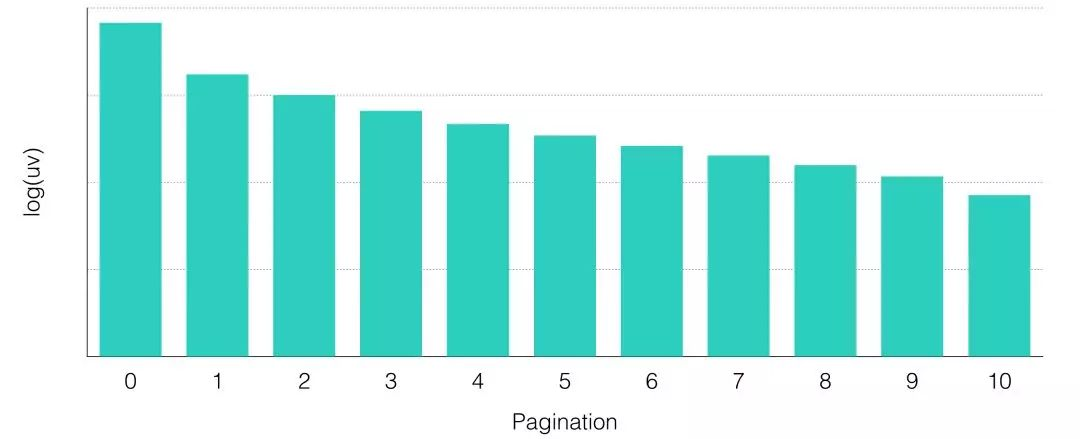
在这样的多轮交互中,我们把推荐系统看作智能体(Agent),用户看作环境(Environment),推荐系统与用户的多轮交互过程可以建模为MDP:
- State:Agent对Environment的观测,即用户的意图和所处场景。
- Action:以List-Wise粒度对推荐列表做调整,考虑长期收益对当前决策的影响。
- Reward:根据用户反馈给予Agent相应的奖励,为业务目标直接负责。
- P(s,a):Agent在当前State s下采取Action a的状态转移概率。
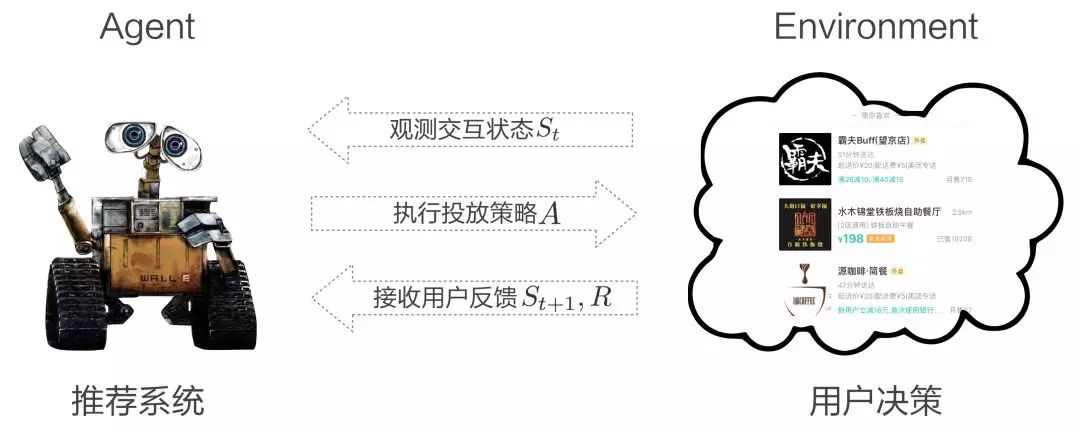
我们的优化目标是使Agent在多轮交互中获得的收益最大化:
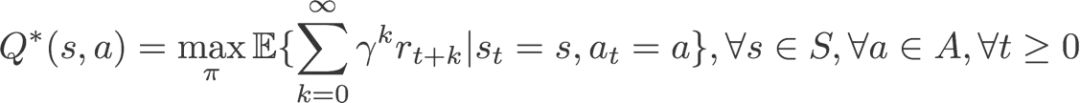
具体而言,我们把交互过程中的MDP建模如下。
2.1 状态建模
状态来自于Agent对Environment的观察,在推荐场景下即用户的意图和所处场景,我们设计了下图所示的网络结构来提取状态的表达。网络主要分为两个部分:把用户实时行为序列的Item Embedding作为输入,使用一维CNN学习用户实时意图的表达;推荐场景其实仍然相当依赖传统特征工程,因此我们使用Dense和Embedding特征表达用户所处的时间、地点、场景,以及更长时间周期内用户行为习惯的挖掘。

这里我们介绍一下使用Embedding特征表达用户行为习惯挖掘的Binary Sequence[2] 方法。我们通过特征工程对用户行为序列做各种维度的抽象,做成一些列离散的N进制编码,表示每一位有N种状态。例如统计用户在1H/6H/1D/3D/1W不同时间窗口内是否有点击行为编码成5位2进制数,把这些数字作为离散特征学习Embedding表达,作为一类特征处理方法。除此之外,还有点击品类是否发生转移、点击间隔的gap等等,在“猜你喜欢”场景的排序模型和强化学习状态建模中都取得了很不错的效果。原因是在行为数据非常丰富的情况下,序列模型受限于复杂度和效率,不足以充分利用这些信息,Binary Sequence可以作为一个很好的补充。
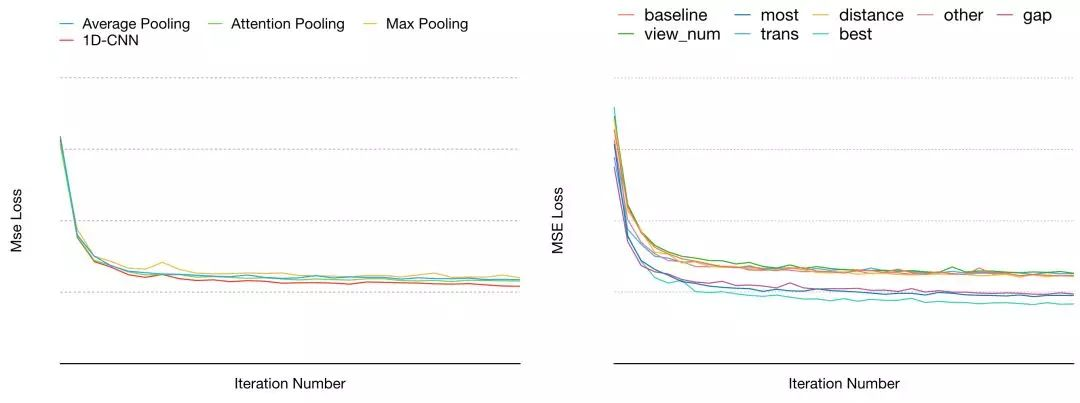
图中左侧是序列模型的部分,分别使用不同的Pooling方式和一维CNN离线效果的对比,右侧是Dense和Embedding特征的部分,分别加入用户高频行为、距离、行为时间间隔、行为次数、意图转移等特征,以及加入所有显著正向特征的离线效果。
2.2 动作设计
“猜你喜欢”目前使用的排序模型由两个同构的Wide&Deep模型组成,分别以点击和支付作为目标训练,最后把两个模型的输出做融合。融合方法如下图所示:
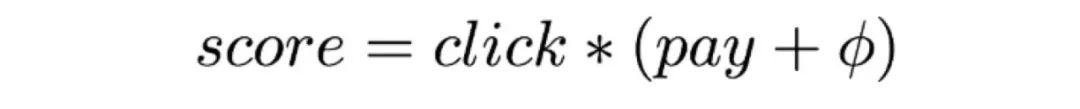
超参数φ的物理意义是调整全量数据集中点击和下单模型的Trade Off,通过综合考虑点击和下单两个任务的AUC确定,没有个性化的因素。我们以此为切入点,使用Agent的动作调整融合超参数,令:
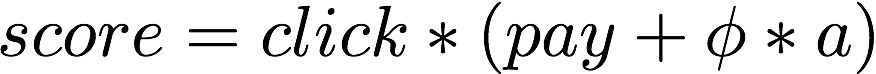
a是由Agent的策略生成Action,这样做有两个好处:其一,我们知道一个较优解是a=1,这种情况下强化学习策略和基线的排序策略保持一致,由于强化学习是个不断试错的过程,我们可以很方便地初始化Agent的策略为a=1,从而避免在实验初期伤害线上效果。其二,允许我们根据物理意义对Action做Clip,从而减轻强化学习更新过程不稳定造成的实际影响。
2.3 奖励塑形
“猜你喜欢”展位的优化核心指标是点击率和下单率,在每个实验分桶中分母是基本相同的,因此业务目标可以看成优化点击次数和下单次数,我们尝试将奖励塑形如下:
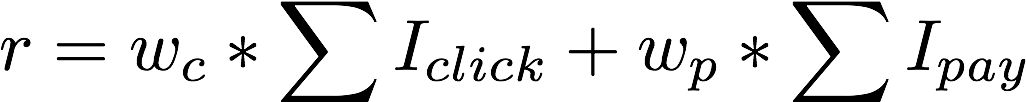
相对于关注每个Item转化效率的Point Wise粒度的排序模型,强化学习的目标是最大化多轮交互中的奖励收益,为业务目标直接负责。
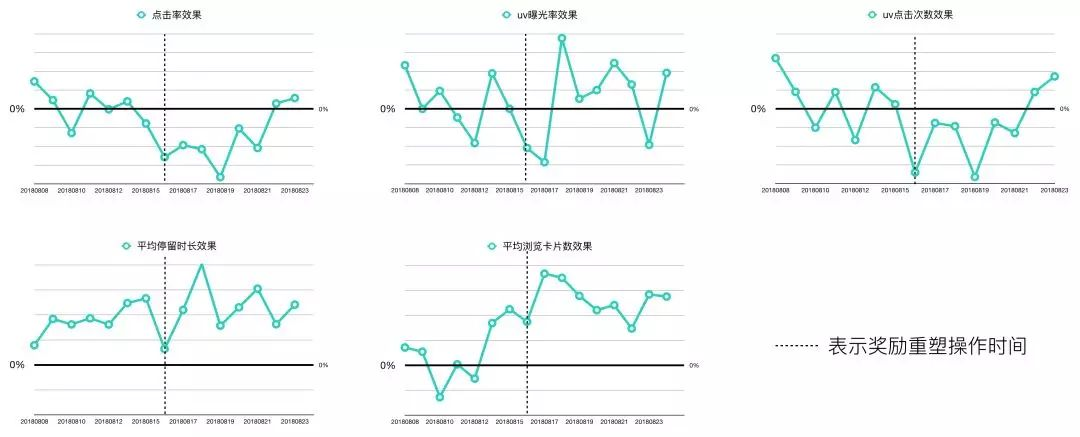
在实验过程中我们发现,强化学习的策略可能上线初期效果很好,在点击和下单指标上都取得了一定的提升,但在后续会逐渐下降,如图前半段所示。在逐层转化效率的分析中,我们发现强化学习分桶的设备曝光率和UV维度点击率有所降低,而用户停留时长和浏览深度稳定提升,这说明Agent学习到了让用户与推荐系统更多交互,从而获取更多曝光和转化机会的策略,但这种策略对于部分强烈下单意图用户的体验是有伤害的,因为这部分用户意图转化的代价变高了,因而对展位的期望变低。针对这种情况,我们在奖励塑形中加入两个惩罚项:
- 惩罚没有发生任何转化(点击/下单)行为的中间交互页面(penalty1),从而让模型学习用户意图转化的最短路;
- 惩罚没有发生任何转化且用户离开的页面(penalty2),从而保护用户体验。
修正后的奖励为: