本文为自监督强化学习 (Self-Supervised Reinforcement Learning/SSRL) 系列介绍的第一部分,本系列主要介绍基于表征学习路线的自监督强化学习(下简称自监督强化学习或自监督表征强化学习)的问题和工作。本部分包括自监督强化学习的简介与部分状态表征 (State Representation) 方法简介。
本系列持续更新,欢迎大家关注交流讨论~
大纲(Outline)
- 简介 (Introduction)
++ 强化学习与函数近似 (Reinforcement Learning and Function Approximation)
++ 强化学习中的表征学习 (Representation Learning in RL)
++ 为什么强化学习智能体 (RL agents) 需要自监督学习?
- 自监督强化学习 (Self-Supervised Reinforcement Learning/SSRL)
++ 自监督状态表征强化学习 (SSRL with State Representation)
++ 自监督动作表征强化学习 (SSRL with Action Representation)
++ 自监督策略表征强化学习 (SSRL with Policy Representation)
++ 自监督任务/环境表征强化学习 (SSRL with Task/Environment Representation)
- 自监督表征强化学习的一些学习问题 (Learning Problems on Representation-based SSRL)
++ 抽象、近似与泛化理论 (Abstraction, Approximation and Generalization)
++ 基于表征进行学习时的一些问题 (Issues when Learning with Representations)
++ 在表征空间中的函数优化 (Optimization in Representation Space)
- 总结
1. 简介
1.1 强化学习与函数近似 (Reinforcement Learning and Function Approximation)
强化学习 (RL) 是机器学习的主要分支之一,是用以学习求解通常建模为马尔可夫决策过程 (Markov Decision Process/MDP) 的序贯决策问题 (Sequential Decision-making Problem) 的有潜力的一种方法。
RL设计的主要要素有以下:
- 环境 Environment,即MDP [公式]
- 智能体 Agent,主要为其策略 (Policy) [公式]
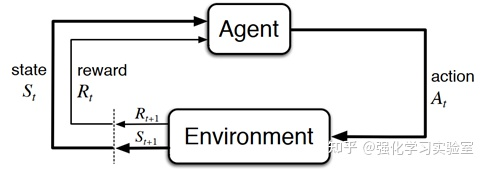
- 智能体与环境交互 Agent-Environment Iteraction(如下图1-1所示):