
第一部分:关于pettingzoo
一、环境列表

二、使用
# Using environments in PettingZoo is very similar to Gym, i.e. you initialize an environment via:
from pettingzoo.butterfly import pistonball_v4
env = pistonball_v4.env()
# Environments can be interacted with in a manner very similar to Gym:
env.reset()
for agent in env.agent_iter():
observation, reward, done, info = env.last()
action = policy(observation)
env.step(action)
第二部分:设计细节介绍
一、简介
二、 MARL中API的状态
三、 API设计原则
四、 API 设计
五、 默认环境
六、 质量的改善
七、 总结
一、简介
本文介绍了PettingZoo,一个在单一优雅的Python API下的不同多agent环境库。PettingZoo的开发目标是加速多agent强化学习的研究,通过创建一套所有研究人员都能轻松访问的基准环境和该领域的标准化API,类似于OpenAI的Gym库对单agent强化学习的作用。PettingZoo的API与其他多agent环境库不同,它的API能够合理地代表多agent强化学习中遇到的所有形式的环境。除此之外,PettingZoo的API与Gym的非常相似,新手可以立即理解,同时还可以访问新的研究可能需要的所有低级特征。
多agent强化学习(MARL)是现代机器学习中有许多最公开的成就--AlphaGo Zero(Silver等人,2017)、OpenAI Five(OpenAI,2018)、AlphaStar(Vinyals等人,2019)。这些成就激发了MARL研究的热潮,仅在2020年,谷歌学者就收录了9480篇讨论多agent强化学习的新论文。尽管有这样的热潮,进行MARL的研究仍然是一个重大的工程挑战。这是因为,与Gym在单agent强化学习中提供的不同,MARL中不存在关于agent如何与环境接口的事实标准API。这使得为新的目的重用现有的学习代码需要大量的努力,消耗了研究人员的时间,阻碍了研究中更彻底的比较。缺乏一个标准化的API也阻碍了MARL中学习库的传播。虽然存在50多个不同的基于Gym的单agent强化库或代码库,但只有5个有意义的MARL库存在(Lanctot等人,2019;Weng等人,2020;Liang等人,2018;Samvelyan等人,2019;Nota,2020)。事实证明,这些基于Gym的学习库的扩散对机器人或金融等领域的应用RL的采用至关重要,没有它们,应用MARL的发展就会受到阻碍。
由于许多独特的情况必须在一个系统下处理,所以MARL以前没有单一的统一的API。API必须合理地支持所有agent轮流单独下棋的游戏,如国际象棋,以及所有agent同时下棋的游戏,如机器人模拟。API还必须合理地支持agent的死亡、agent的增加、agent顺序的改变(如Uno)、每次环境初始化时agent的不同组合,以及集中critic方法的单独全局观察。这种情况的多样性似乎导致了MARL社区的一种隐性信念,即没有一个API可以处理所有这些事情,更不用说一个高效的、类似Gym的API了。
Gym为单agent强化学习解决的MARL中存在的最后一个问题是,许多流行的MARL环境都没有得到维护,需要大量的工程建设才能使用。这尤其会使MARL的研究变得毫无成效,或者是大学水平的研究人员无法接触到的。
本文介绍了PettingZoo,一个用于多agent强化学习的类似gym的库。在本文中,我们调查了我们如何能够创建一个简单的、类似Gym的API,能够首次处理所有种类的MARL环境,该库背后的设计理念,我们包括的流行的未维护的MARL环境集,以及我们在此首次介绍的新环境集。我们还简要地调查了一些有趣的生活质量特征,这些特点是我们从Gym的开发中得到的教训所启发出来的。
二、 MARL中API的状态
由于Gym在整个领域的影响,我们将简单回顾一下它的API。它是一个简单的Python API,如图1所示。请注意,只要有琐碎的、基本的RL知识,它就很容易阅读。

MARL的API在很大程度上继承了两种最常用于描述MARL的数学模型--部分可观察的随机博弈(POSG)和广义形式博弈(EFG)。MARL的大部分API都是围绕POSG模型,包括后面描述的PettingZoo中所有默认游戏的原始实现(除经典外),以及许多其他主要环境(Lowe等人,2017;Zheng等人,2017;Gupta等人,2017;Liu等人,2019;Liang等人,2018)。在这种模式下,环境一次为所有agent采取一个行动,并一次为所有agent返回一个观察。所有的agent真正地完全平行工作。RLlib的多agent API很好地说明了这一概念,在Gym API的简单扩展中传递了动作、观察和奖励的agent key字典。

这个模型的问题是,改变agent的数量是很尴尬的(学习代码将不得不应付字典突然改变的大小),而且支持严格的回合制游戏,如国际象棋,需要不断地为不行动的agent传递假动作。这个API也没有提供像集中式critic方法所需要的单独提供全局观察的方法。
严格基于回合制的简单游戏通常用单人gymAPI建模(Ha, 2020),由环境来交替控制哪个agent。由于游戏模型所做的隐含工作的混乱性质,以及处理agent顺序变化或agent死亡的困难,我们不知道这曾经为2个以上的agent做过。在这些情况下,更常见的是用EFG式的API对游戏进行建模,如OpenSpiel(Lanctot等人,2019)的情况,其API如图3所示。

虽然OpenSpiel是一个设计得非常好的软件包,但在它的API中,状态编码了环境的整个历史,以允许回溯。这意味着对于像Atari这样有大量观测数据的游戏来说,该API在计算上是不可行的。它也远不如Gym的API简单和Pythonic。
三、 API设计原则
在设计一个可以通用于MARL的API时,我们着重于两个主要的驱动原则。
3.1. API应该让初学者一眼就能看懂,并尽可能地与Gym相似。
Gym API的美妙之处在于,任何技能水平的人都可以轻松地理解它并为它编写代码。对于任何像这样的API来说,要成为一个标准,可用性是一个基本要求。此外,一个标准的多agent API应该尽可能地与Gym相似,因为每个研究者都已经熟悉Gym。
Gym做得非常好并且被广泛重复使用的一个组件是空间对象集。Gym环境的允许行动和观察是通过空间对象来定义的,这些对象指定了允许值的范围和类型(例如,数组中的连续值或n×m n-m的离散值)。这些是一个设计良好的标准,所以我们选择自己重用它们,以获得更好的互操作性和易于采用。
3.2. API应该将环境建模为agent环境循环游戏
agent环境循环("AEC")游戏本质上是每个agent按顺序行动的POSG(Terry等人,2020b)。这很有用,因为在严格的平行环境中,每个agent的顺序步并不是一个问题(不像使用大量的假动作来一次步入一个严格顺序的环境)。AEC游戏模型还有一个有趣的概念,即 "下一个agent "函数,它就像一个传统的环境转移函数,但对agent而言。通过有一个函数作为API的一部分,类似于生成下一个要采取行动的agent,改变agent顺序和agent死亡或生成的问题得到了非常干净的处理。将环境建模为AEC游戏也有助于防止某些难以调试的错误,正如原始论文中所概述的。
四、 API 设计
4.1. 基本API.
PettingZoo的API如图4所示,与Gym API(图1)的强烈相似性应该是显而易见的--每个agent向一个函数提供一个动作,而步则作为观察、奖励、完成、信息的返回值接收。观察和状态空间也使用与Gym完全相同的空间对象。虽然这是Gym API的简单扩展,但值得注意的是,尽管有很多尝试,但从来没有人这样做过(Lanctot等人,2019;Liang等人,2018;Zha等人,2019;Samvelyan等人,2019;Zheng等人,2017;Gupta等人,2017;刘等人,2019;Lowe等人,2017;Koul,2019;Har,2020;Vinitsky等人,2019)。有鉴于此,与Gym API的简单性和相似性是一个显著的特点。和方法的特点也与Gym的特点相同,接近Gym的特点,每当调用时都会向屏幕显示代表环境的当前视觉框架。reset方法的特征同样与Gym相同--它在游戏结束后将环境重置为初始配置。PettingZoo实际上只有两个与常规Gym API不同的地方--最后的agent_iter方法和相应的迭代逻辑。

4.2. agent_iter方法
agent_iter方法是一个环境的生成器方法,它返回环境将采取行动的下一个agent。因为环境提供了下一个agent的行动,这干净地抽象了围绕改变agent顺序、agent生成和agent死亡的任何问题。这种生成方式也与AEC游戏模型中的下一个agent特征相类似。
4.3. last方法
多agent环境的一个奇怪的方面是,从一个agent的角度来看,其他agent是环境的一部分。在单agent的情况下,观察和奖励可以立即给出,而在多agent的情况下,一个agent必须等待所有其他agent采取行动,然后它的观察、奖励和可以完全做信息确定。出于这个原因,这些值是由最后一个方法给出的,然后它们可以被传递到一个策略中,以选择一个行动。比这种方法更不健全的应用将不允许改变agent的顺序等特征(如Uno中的反向卡)。
4.4. 额外的API特征
agents是环境中所有agent的列表,为字符串。 rewards, dones, infos, action_spaces和是每个属性的agent键入dictionarobservation_spaces ies(注意,奖励是最近行动产生的瞬时奖励)。这些允许访问轨迹上所有点的agent属性,无论选择哪一个。observe(agent)方法通过传递其名称作为参数来提供对单个agent的观察,如果你需要在一个不寻常的环境中观察一个agent,这可能很有用。agent_selection方法返回当前可以对每个agent_iter采取行动的agent。
允许访问所有这些低层次的信息的动机是让研究人员尝试新的、不寻常的实验。多Agent RL的空间还没有被全面探索,而且有许多完全合理的理由,你可能想要访问其他Agent的奖励、观察等等。对于一个新兴领域的通用API来说,它必须允许访问研究人员可能想要的所有信息。出于这个原因,除了标准的高层API之外,我们还允许访问一套相当简单的低层属性和方法。正如我们在第4.6小节中所概述的那样,我们对PettingZoo的结构进行了调整,包括这些低级别的特征,不会引入工程开销。
4.5. 稳健地支持可变的agent集
PettingZoo API的一个目标,除了对添加或删除agent有很好的支持外,还支持progenesque环境(Cobbe等人,2020),其中不同的agent集可能出现在每次重置。支持这一特征对于能够模拟许多现实世界的场景非常重要(例如,在生产中协调来自不同制造商的自动驾驶汽车)。PettingZoo通过拥有一个不可变的属性来处理这个问题,该属性列出了所有可能存在于环境中的agent,在任何时候。重置环境后,agents属性可以被访问,并列出所有当前活动的agent。由于类似的原因,num_agents、rewards、dones、infos和agent_selection在重置之前是不可用的。
4.6. 环境创建和并行API
PettingZoo环境实际上只暴露了reset、seed、step、observe、render和base methclose ods以及agent、rewards、dones、infos和agent_iter基础属性。然后,这些都被包裹起来以添加方法。只让环境实现最后的原始方法使得创建新环境更加简单,并减少了代码的重复。这有一个很有用的副作用,就是允许所有的PettingZoo环境在需要时通过简单地编写一个新的装饰器就可以很容易地改变成另一种API。实际上,我们已经为默认环境做了这件事,并为它们添加了一个额外的 "并行API",通过装饰器与基于RLlib POSG的API几乎完全相同。我们添加了这个辅助API,因为在有非常多的agent的环境中,这可以通过减少Python函数调用的数量来改善运行时间。
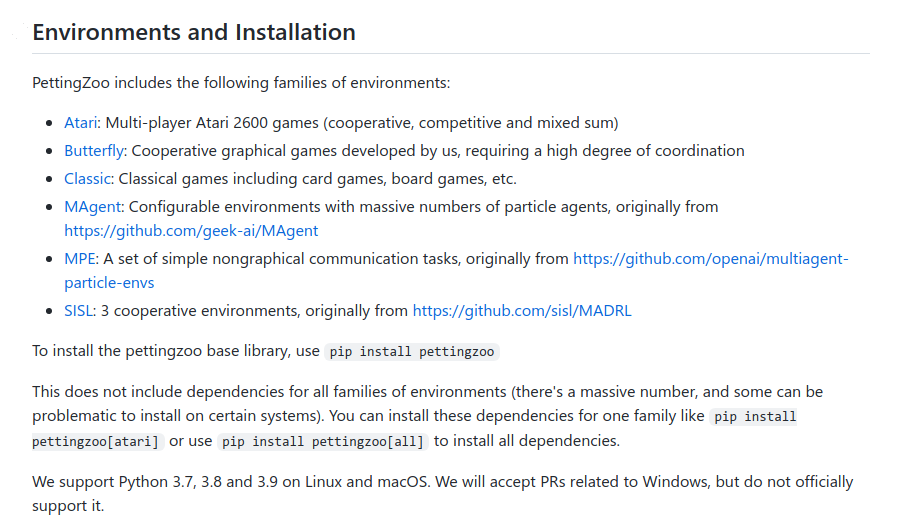
五、 默认环境
与Gym类似,我们希望在一个软件包中包括流行的和有趣的环境,并以一种容易使用的格式。我们包含的一半环境类(MPE、MAgent和SISL),尽管它们很受欢迎,但以前只作为未维护的 "研究级 "代码存在,不能通过pip安装,需要大量的维护才能运行。它们还需要大量的调试、代码回顾、代码清理和文档,才能达到生产级别的状态。我们另外还包括Terry和Black(2020)的多人Atari游戏。蝴蝶环境类是我们创造的新环境,我们认为它对多agent强化学习提出了重要的、新的挑战。最后,我们包括经典类--在RL文献中流行的经典棋盘和纸牌游戏。
Atari游戏代表了强化学习中最流行和最有代表性的一类基准。最近,拱廊学习环境的多agent分叉被创建,允许对Atari标志性的多人游戏进行程序化控制和奖励收集(Terry和Black,2020)。如同在Atari的单人游戏环境中,观察的是游戏的渲染框架,它是所有agent之间共享的,所以不存在部分观察性。这些游戏大多具有竞争性或混合性的奖励结构,使它们适合于对抗性和混合强化学习的一般研究。特别是,Terry和Black(2020)将这些游戏分为7种不同类型。1v1锦标赛游戏,混合和生存游戏(图5a.所示的太空入侵者就是一个例子),竞争性赛车游戏,长期策略游戏,2v2锦标赛游戏,一个四人自由竞争游戏和一个合作游戏。
蝴蝶
在包括的所有环境中,大多数是竞争性的。我们想用一组有趣的图形化合作环境来补充这一点。图5b中描述的活塞球,是一个活塞需要协调将球向左移动的环境,而只能观察到屏幕的局部。它需要学习非微妙的突发行为和间接交流才能表现良好。《骑士射手僵尸》游戏,需要玩家合作,在接近的僵尸到达玩家之前击败它们。它被设计成一个快节奏的、图形上有趣的战斗游戏,具有部分可观察性和异构agent,其中实现良好的性能需要异常高水平的agent协调。在两个不同的乒乓球拍合作中,尽可能长时间地保持一个球的运动。它的目的是一个非常简单的合作连续控制型任务,有异构的agent。是监狱设计的,是MARL中最简单的游戏,并作为一个调试工具使用。在这个环境中,没有agent与其他agent有任何互动,当每个agent从牢房的一端走到另一端时,它只是获得1的奖励。"展望 "是一个对传统方法非常具有挑战性的游戏--它有两类agent,具有不同的目标、行动空间和观察空间(这是目前许多合作MARL算法难以解决的问题),并且具有非常稀疏的奖励(这是所有RL算法难以解决的问题)。它旨在成为MARL的一个非常困难的基准,与Montezuma's Revenge相同。
经典游戏
长期以来,经典的棋牌游戏是强化学习中最受欢迎的一些环境(Tesauro,1995;Silver等人,2016;Bard等人,2019)。我们在RLCard(Zha等人,2019)中包括所有标准的多人游戏。迪珠、拉米、扑克、斗地主极限德州无限制德州扑克、麻将、扑克和乌诺。我们另外还包括所有AlphaZero游戏,使用相同的观察和行动空间--国际象棋和围棋。我们最后还包括了西洋双陆棋、四子棋、跳棋、连连看、剪刀石头布、斯波克和井字棋,以增加一套多样化的简单、流行的游戏,以便对RL方法进行更有力的基准测试。

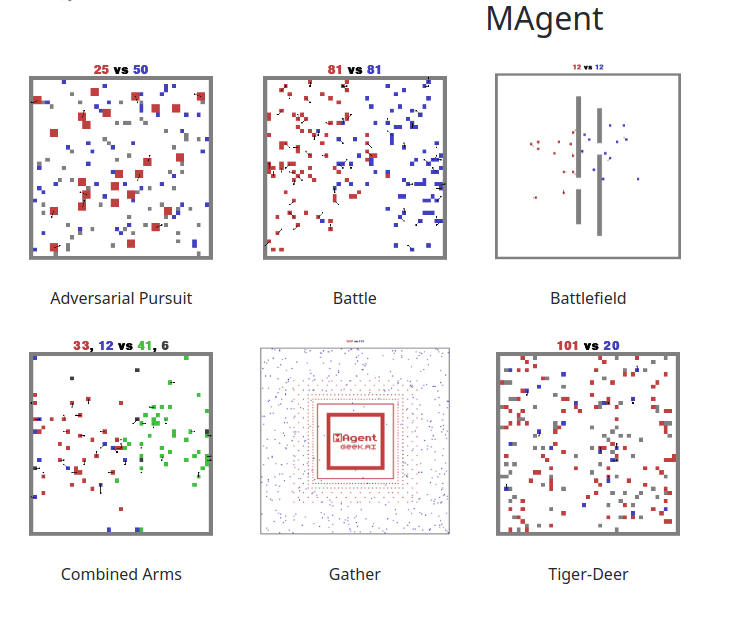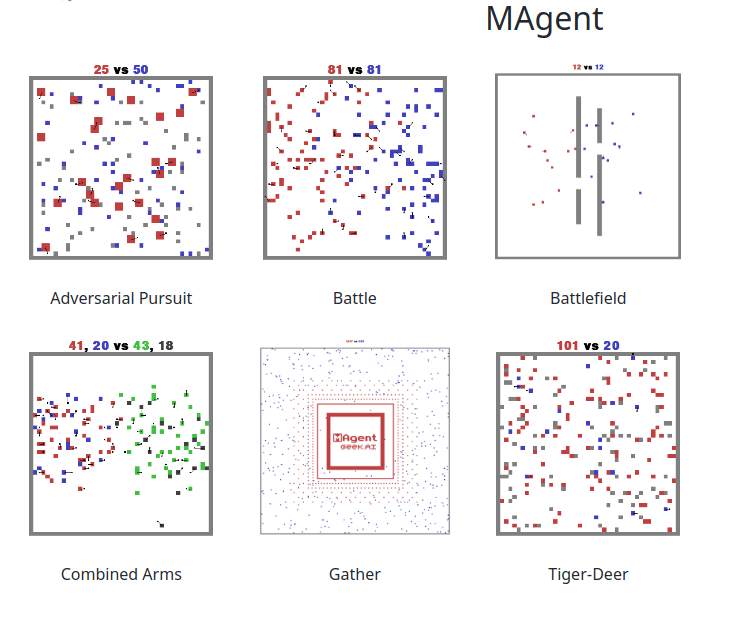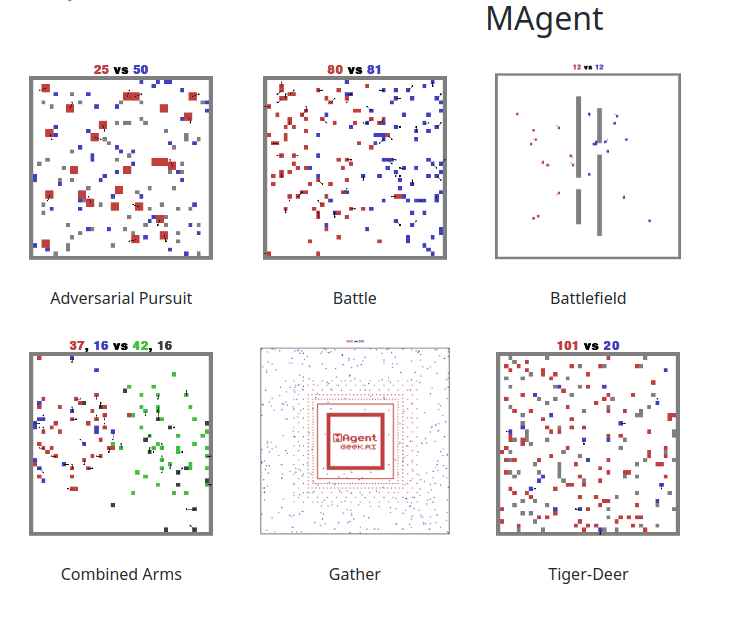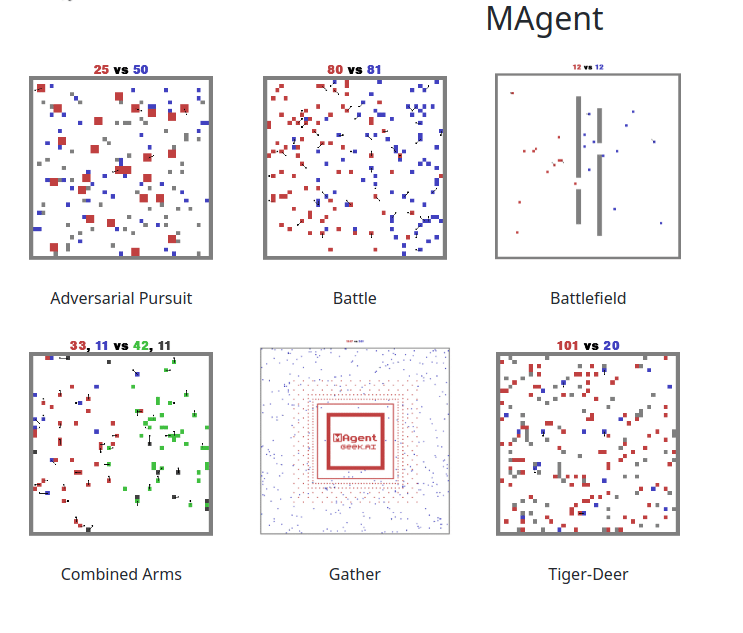
Zheng等人(2017)的MAgent库被介绍为一个可配置和可扩展的环境,可以支持成千上万的互动agent。这些环境大多被研究为突发行为(Pokle,2018)、异构agent(Subramanian等人,2020)和具有许多agent的高效学习方法(Chen等人,2019)的设置。我们包括一些预设的配置,例如图5d所示的环境Adversarial Pursuit。我们对原MAgent论文中使用的预设配置做了一些改变。战斗环境中的全局 "最小地图 "观测默认是关闭的,这需要agent之间的隐性交流以发生复杂的突发行为。和中的奖励也稍稍进行了Gather Tiger-Deerchanged,以防止出现的行为成为奖励结构的直接结果。
多Agent粒子环境(MPE)是作为Mordatch和Abbeel(2017)的一部分引入的,并作为Lowe等人(2017)的一部分首次发布。这些是9个面向通信的环境,粒子agent可以(有时)移动、通信、看到对方、互相推搡,并与固定地标互动。环境是合作性的,竞争性的,或需要团队游戏。它们在一般MARL方法Lowe等人(2017)、突发通信(Mordatch和Abbeel,2017)、团队游戏(Palmer,2020)等研究中一直很受欢迎。作为将其纳入PettingZoo的一部分,我们将行动空间转换为离散空间,这是运动和交流行动可能性的笛卡尔乘积。我们还添加了全面的文档,对任何局部奖励的塑造进行了参数化(默认设置与Lowe等人(2017)的设置相同),并制作了一个单一的渲染窗口,该窗口捕获了所有agent的所有活动(包括通信),使其更容易可视化。
我们最后包括了Gupta等人(2017)介绍的三种合作环境。追逐、水世界和多行者。是一个标准的追逐-逃避游戏ViPursuit dal等人(2002),其中追逐者被控制在一个随机生成的地图中。追击者通过四面包围随机生成的逃避者而获得奖励。 是一个连续控制游戏,水世界的追击者合作追捕食物目标,同时试图避免毒物目标。图5f)是Multiwalker是一个更具挑战性的连续控制任务,是基于Gym的环境。在Multiwalker中,一个BipedalWalker包被放在三个独立控制的机器人腿上。包裹每向前水平移动一个单元,每个机器人都会得到一个小的正向奖励,而掉落包裹则会得到一个大的惩罚。
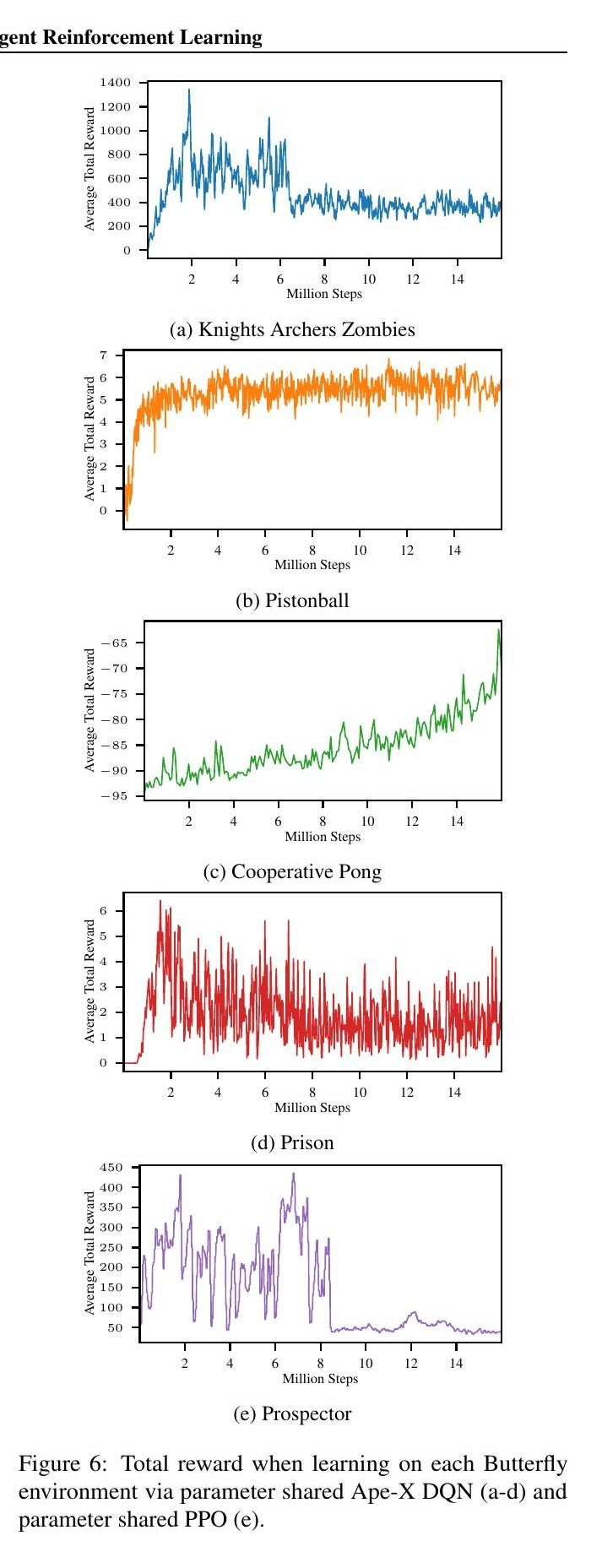
5.1. Butterfly基线
PettingZoo中实现的所有环境都包括基线,以提供对环境难度的总体感觉,并作为初步比较的对象。我们在这里为本库首次引入的Butterfly环境做了这个工作;在引入所有其他环境的论文中也有类似的基线。我们对所有环境使用了全参数共享(Gupta等人,2017)的ApeX DQN(Horgan等人,2018),除了Prospector,我们对它使用了来自RLLib(Liang等人,2018)的PPO(Schulman等人,2017),因为它有一个连续的行动空间。我们的结果显示在图6中。预处理和超参数的细节包括在所有的预处理都是用SuperSuit包装库(Terry等人,2020a)完成的。环境、训练日志和保存策略的代码可在https://github.com/ pettingzoopaper/pettingzoopaper。
六、 质量的改善
随着OpenAI的gym在单体agentRL研究中变得无处不在,它的广泛使用已经照亮了类似框架的几个潜在改进领域。
6.1. 本质上支持环境配置
我们相信,通过参数支持配置的环境应该是RL研究中的规范。这使得研究人员可以很容易地测试不同兴趣场景的影响,而不需要fork和手动编辑环境,并有助于重现性。虽然在默认的Gym环境中不存在,但这在很大程度上已经成为第三方Gym环境的标准。受此启发,我们在所有默认的PettingZoo环境中包含了所有你想控制的环境参数的合理设置。
6.2. 文档
文档是一个用户友好型软件库的基本组成部分,使用Gym的一个主要挑战是必须经常参考源代码和查看代码标注来学习环境的基本属性(如奖励结构、观察和行动空间属性等)。这对研究人员来说是很耗时的,对许多初学者来说也是不可及的。出于这个原因,我们为PettingZoo创建了一个非常全面的文档网站,以维基百科风格的格式,清楚地包括了许多人需要的所有信息(奖励结构、配置参数、状态空间组件、AEC图等)。
6.3. 测试和调优建议
与Gym环境合作的一个痛点是,没有集中的测试来确保你所创建的第三方环境符合API。我们相信这些是开发者可及性的一个关键特征,并已将其添加到PettingZoo。这些测试还包括关于环境设计的最佳实践的非常详细的建议,以尝试和改善PettingZoo生态系统的一般可访问性质量,其灵感来自于深受欢迎的Rust编译器的调整信息。
6.4. 有用的错误信息
在使用Gym时,触发任何错误都会产生一个回溯,需要慢慢解码才能找到实际问题。这浪费了研究人员的时间,使其在启动时更具挑战性。为了帮助解决这个问题,PettingZoo为所有我们知道的常见错误提供了特殊的错误信息,这也是受到Rust编译器的启发。这些错误信息以装饰器的形式包括在内,以便它们可以很容易地被添加到第三方环境中。
七、 总结
本文介绍了PettingZoo,一个在一个简单的API下由许多不同的多agent强化学习环境组成的Python库,类似于OpenAI的Gym库的多agent版本,并概述了这样一个API是如何首次实现的。
强化学习系统有两个主要组成部分,环境和学习的agent。如果没有一个标准化的环境基础,研究的进展是通过设计和建立环境和agent(就像MARL的情况一样)。PettingZoo的主要贡献是,它通过环境的标准化和民主化,使更多的研究关注于agent。我们希望这能使多agent强化学习的研究加速并蓬勃发展。
我们知道PettingZoo API有一个明显的限制。拥有明显超过10,000个agent(或潜在agent)的游戏会有有意义的性能问题。这是因为在创建环境时需要指定观察空间、行动空间和潜在的agent名称。我们认为这是一个实际可接受的限制。
我们看到未来工作的三个明显方向。首先是在我们的API下添加更多有趣的环境(可能来自社区,就像Gym那样)。虽然我们已经包括了大量的环境,但还有一些有价值的环境:社会连续困境游戏的开源实现(Vinitsky等人,2019),以及《星际争霸2》多agent挑战("SMAC")环境(Samvelyan等人,2019)。这些原本没有被默认包括在内,因为它们是积极维护的,所以在我们看来是较低的优先级。我们设想的第二个方向是提供一项服务,允许不同研究人员的agent在竞争性游戏中相互竞争,利用标准化的API和环境集。最后,我们设想开发程序化生成的多agent环境,以测试方法的泛化程度,类似于Gym procgen环境,利用PettingZoo API的能力来处理重置后不同数量和种类的agent(Cobbe等人,2019)。