前言
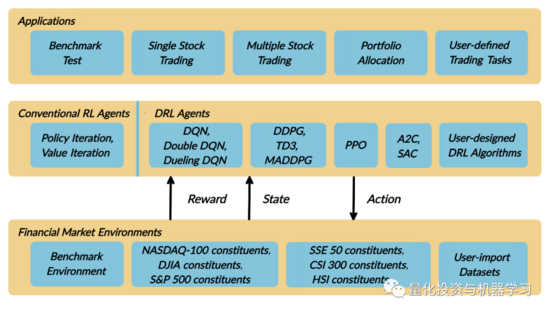
深度强化学习(DRL)已被公认为量化投资中的一种有效方法,因此获得实际操作经验对初学者很有吸引力。然而,为了培养一个实用的DRL 交易agent,决定在哪里交易,以什么价格交易,以及交易的数量,会涉及非常多的内容和前期具有挑战性的开发和测试。
问题定义
这个问题是为单只股票交易而设计的一个自动化交易解决方案。我们将股票交易过程建模为马可夫决策过程交易过程(MDP)。然后我们将交易目标表述为一个最大化问题。
强化学习环境的组成部分:
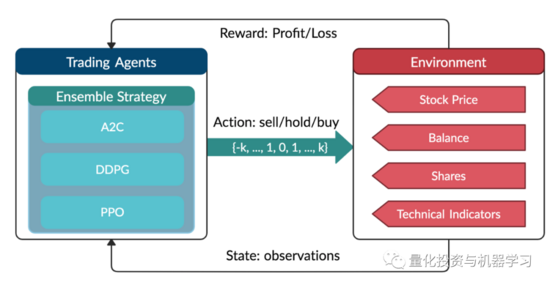
Action
操作空间允许agent与环境交互的操作。一般情况下,a∈a包含三个动作:a∈{−1,0,1},其中−1,0,1表示卖出、持有和买入。同时,一个Action可以对多份股票进行。我们使用一个动作空间{−k,…,−1,0,1,…,k},其中k表示股份的数量。例如,“买10股Apple”或“卖10股Apple”分别是+10或-10。
Reward function
r (s,a,s ′)是agent学习更好的激励机制。当a在状态s时,达到新的状态s '时,投资组合值的变化,即r(s, a, s ') = v '−v,其中v '和v分别表示状态s '和s时的投资组合值。
State
状态空间描述agent从环境中接收的观察值。正如交易者在执行交易之前需要分析各种信息一样,我们的交易agent也观察了许多不同的特征,以便在交互环境中更好地学习。
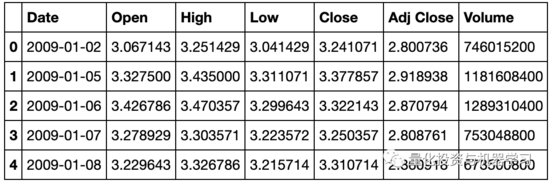
本案例只研究单只股票,数据来自雅虎财经API。数据包含开高低收和成交量。
加载相关库
# Install the unstable development version in Jupyter notebook:
!pip install git+https://github.com/AI4Finance-LLC/FinRL-Library.git
import pkg_resources
import pip
installedPackages = {pkg.key for pkg in pkg_resources.working_set}
required = {'yfinance', 'pandas', 'matplotlib', 'stockstats','stable-baselines','gym','tensorflow'}
missing = required - installedPackages
if missing:
!pip install yfinance
!pip install pandas
!pip install matplotlib
!pip install stockstats
!pip install gym
!pip install stable-baselines[mpi]
!pip install tensorflow==1.15.4
# import packages
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('Agg')
import datetime
from finrl.config import config
from finrl.marketdata.yahoodownloader import YahooDownloader
from finrl.preprocessing.preprocessors import FeatureEngineer
from finrl.preprocessing.data import data_split
from finrl.env.environment import EnvSetup
from finrl.env.EnvMultipleStock_train import StockEnvTrain
from finrl.env.EnvMultipleStock_trade import StockEnvTrade
from finrl.model.models import DRLAgent
from finrl.trade.backtest import BackTestStats, BaselineStats, BackTestPlot
数据下载
FinRL 使用YahooDownloader类提取数据。
class YahooDownloader:
"""Provides methods for retrieving daily stock data from
Yahoo Finance API
Attributes
----------
start_date : str
start date of the data (modified from config.py)
end_date : str
end date of the data (modified from config.py)
ticker_list : list
a list of stock tickers (modified from config.py)
Methods
-------
fetch_data()
Fetches data from yahoo API
保存数据:
data_df = YahooDownloader(start_date = '2009-01-01',
end_date = '2020-09-30',
ticker_list = ['AAPL']).fetch_data()
view raw
数据预处理
技术指标构建,inRL使用一个FeatureEngineer类来预处理数据。
class FeatureEngineer:
"""Provides methods for preprocessing the stock price data
Attributes
----------
df: DataFrame
data downloaded from Yahoo API
feature_number : int
number of features we used
use_technical_indicator : boolean
we technical indicator or not
use_turbulence : boolean
use turbulence index or not
Methods
-------
preprocess_data()
main method to do the feature engineering
"""
特征工程:
data_df = FeatureEngineer(data_df.copy(),
use_technical_indicator=True,
tech_indicator_list =
tech_indicator_list,use_turbulence=False,
user_defined_feature = True).preprocess_data()
环境搭建
我们将金融建模定义为一个马尔可夫决策过程(MDP)问题。训练过程包括观测股价变化,采取动作和收益的计算,使agent调整其相应的策略。通过与环境的互动,交易agent将得到一个交易策略,随着时间的推移,最大化收益。
交易环境基于OpenAI Gym框架。
环境设计是DRL中最重要的部分之一,因为它会因应用程序和市场的不同而有所不同。我们不能用股票交易的环境来交易比特币,反之亦然。
操作空间描述允许agent与环境进行交互操作。通常,动作a包括三个动作:{- 1,0,1},其中- 1,0,1表示卖出、持有和买入。同时,一个动作可以对多个股份进行。我们使用一个动作空间{-k,…,- 1,0,1,…,k},其中k表示需要买入的股份数量,-k表示需要卖出的股份数量。连续动作空间需要归一化到[- 1,1],因为策略是在高斯分布上定义的,需要归一化和对称。
在本文中,我们将k=200设置为AAPL的整个操作空间为:200*2+1=401。
FinRL使用EnvSetup类来设置环境:
class EnvSetup:
"""Provides methods for retrieving daily stock data from
Yahoo Finance API
Attributes
----------
stock_dim: int
number of unique stocks
hmax : int
maximum number of shares to trade
initial_amount: int
start money
transaction_cost_pct : float
transaction cost percentage per trade
reward_scaling: float
scaling factor for reward, good for training
tech_indicator_list: list
a list of technical indicator names (modified from config.py)
Methods
-------
fetch_data()
Fetches data from yahoo API
"""
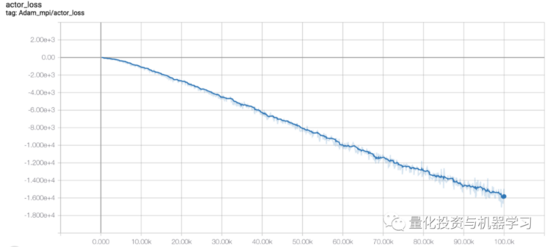
实现DRL算法
DRL算法的实现基于OpenAI Baselines和Stable Baselines。Stable Baselines是OpenAI Baselines基线的一个分支,包括主要的结构重构和代码清理。
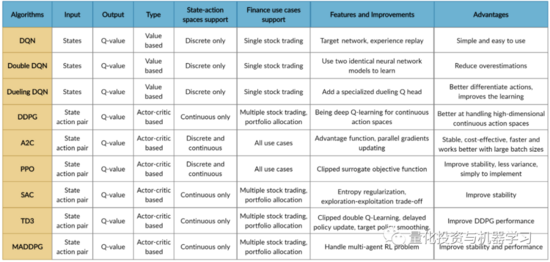
FinRL库经过微调的标准DRL算法,如 DQN、DDPG、Multi-Agent DDPG、PPO、SAC、A2C和TD3。还允许用户通过调整这些DRL算法来设计他们自己的DRL算法:
FinRL 使用 DRLAgent 类来实现算法:
class DRLAgent:
"""Provides implementations for DRL algorithms
Attributes
----------
env: gym environment class
user-defined class
Methods
-------
train_PPO()
the implementation for PPO algorithm
train_A2C()
the implementation for A2C algorithm
train_DDPG()
the implementation for DDPG algorithm
train_TD3()
the implementation for TD3 algorithm
DRL_prediction()
make a prediction in a test dataset and get results
"""
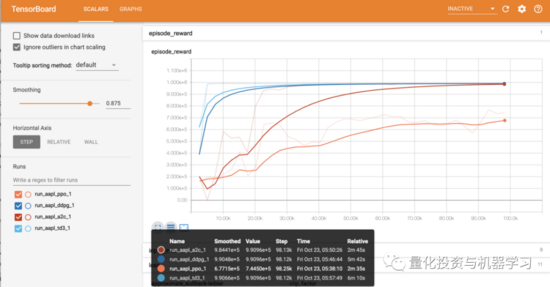
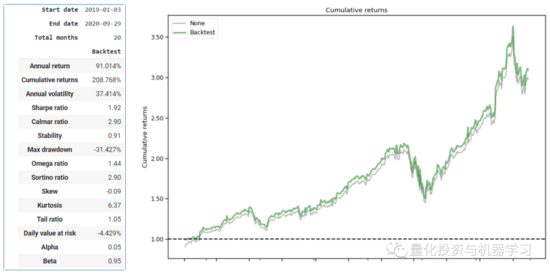
模型训练
print("==============Model Training===========")
now = datetime.datetime.now().strftime('%Y%m%d-%Hh%M')
td3_params_tuning = {'batch_size': 128,
'buffer_size':50000,
'learning_rate': 0.0001,
'verbose':0,
'timesteps':20000}
agent = DRLAgent(env = env_train)
model_td3 = agent.train_TD3(model_name = "TD3_{}".format(now),
model_params = td3_params_tuning)
在本文中我们使用了4种DRL模型,即 PPO、A2C、DDPG和TD3。