链接:https://arxiv.org/pdf/1709.06560.pdf
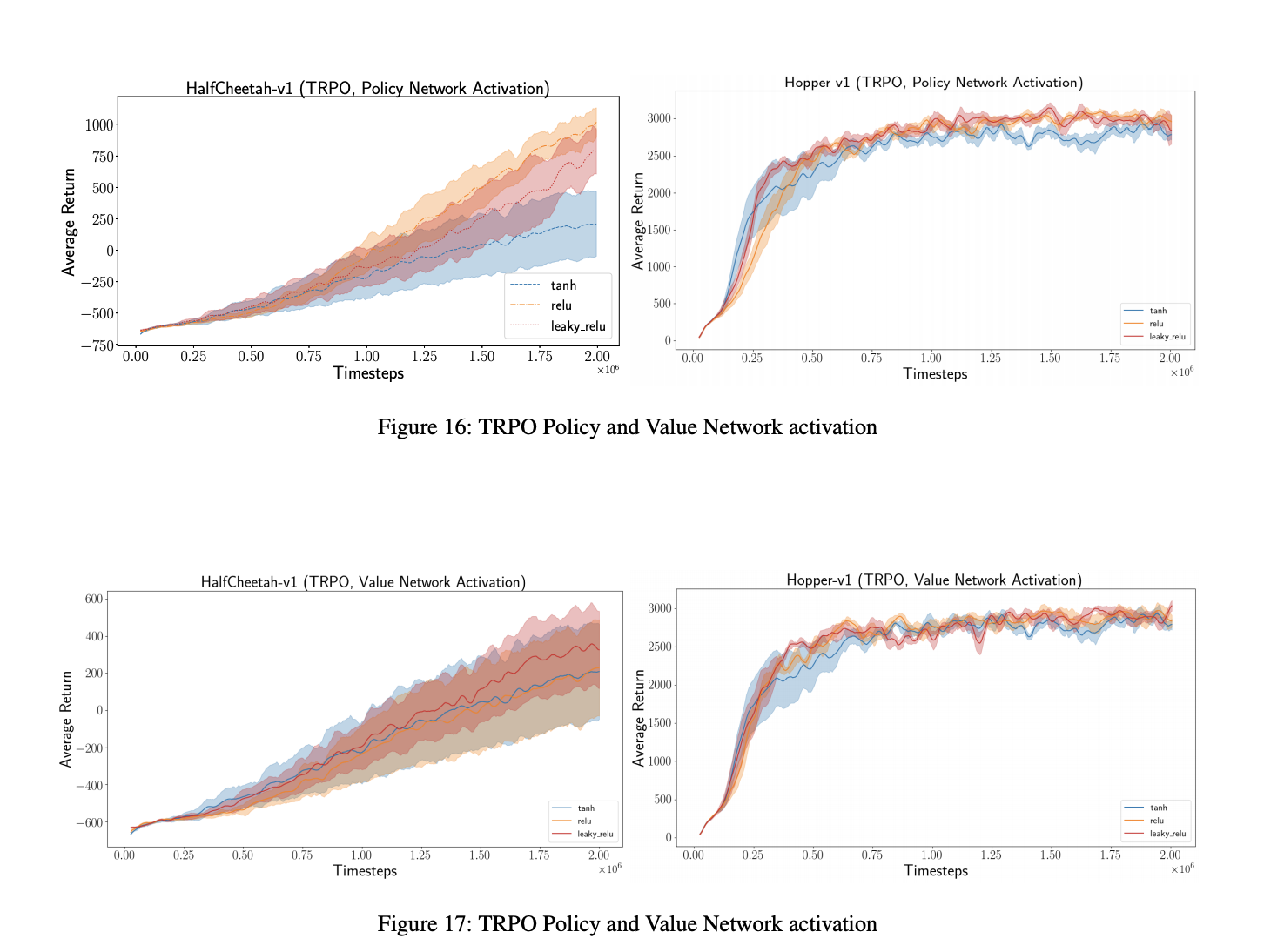
摘要:In recent years, significant progress has been made in solving challenging problems across various domains using deep re- inforcement learning (RL). Reproducing existing work and accurately judging the improvements offered by novel meth- ods is vital to sustaining this progress. Unfortunately, repro- ducing results for state-of-the-art deep RL methods is seldom straightforward. In particular, non-determinism in standard benchmark environments, combined with variance intrinsic to the methods, can make reported results tough to interpret. Without significance metrics and tighter standardization of experimental reporting, it is difficult to determine whether im- provements over the prior state-of-the-art are meaningful. In this paper, we investigate challenges posed by reproducibility, proper experimental techniques, and reporting procedures. We illustrate the variability in reported metrics and results when comparing against common baselines and suggest guidelines to make future results in deep RL more reproducible. We aim to spur discussion about how to ensure continued progress in the field by minimizing wasted effort stemming from results that are non-reproducible and easily misinterpreted. Introduction