2021 IDEA大会由深圳市福田区人民政府、深圳市福田区科技创新局和粤港澳大湾区数字经济研究院(International Digital Economy Academy,简称“IDEA”)联合举办。
金融强化学习开源框架FinRL在粤港澳大湾区数字经济研究院(IDEA)上荣幸被沈向洋院士推介,作为六大前沿产品之一。

为什么强化学习在金融上比较适用?
在金融市场里,例如股票交易就属于序贯决策(Sequential Decision),又可以叫顺序决策、序列决策,意思就是按时间顺序做了一系列决策,这个一系列的决策会相互影响,之前做的决策会影响后面做的决策。这个跟有监督学习是有本质区别的,有监督的场景每次做决策都是独立的,比如说分类,上一个图片是猫是狗的分类,对下一个图片上是猫是狗的分类是没有关联的。
强化学习要解决的就是序贯决策问题。可以用马尔可夫决策来建模。
在金融任务中,天然地存在一个reward function,即: 某段时间内,智能体(agent)获得的累积收益,就是我们的优化目标。这个优化信息足够稠密(每一步都有reward信号),足够准确(好的策略和差的策略,它们得到的累积reward有明显的区别)。
此外,因为金融的仿真环境,甚至真实环境都没有实体,数据的采集/获取简单(相比实体机器人来说),动作的执行相对精准,仿真与现实的gap (real to simulate 的 gap) 比较小,容易控制。
因此RL适合金融任务。
以往的监督学习,需要人类的先验知识去训练出我们需要的策略,人工痕迹过多。而强化学习可以自己学出来一个好的策略,我们只需要提供足够的市场数据,并设计好的算法去利用算力学出这个交易策略即可。与监督学习的方法相比,强化学习最多会带有数据的偏见,而不会被人类(不一定准确的先验知识)的偏见影响。
用强化学习在金融上模拟什么?如何模拟?
可以直接让强化学习智能体在真实市场中学习,但是真实市场有局限,研究人员不能像神明一样掌握全局信息。
因此我们要搭建500GPU的“金融风洞”。让所有不同的智能体/交易策略,在这个“金融风洞”上进行交易模拟,这样我们就有能力收集所有智能体的所有交易行为。在研究人员掌握全局信息后,我们对金融行为的理解和分析将会上升一个层级,例如黑天鹅事件。金融智能体也能在一个更加可控,更加贴近现实的环境中训练,在充足的验证下,它的可靠性也能获得跃升。
在“金融风洞”中,我们提供不同类型的买方卖方的交易策略,让他们在虚拟盘上交易。模拟真实市场中多个智能体进行博弈的场景。因此需要500GPU这样等级的GPU集群。
为了支持不同的交易任务,我们需要使用各种环境训练多个agents。这需要多样化的基于强化学习的市场环境。当前的工作更多地针对开发交易策略而不是市场模拟。(可以理解,因为大家都想着赚钱)
用强化学习开发的交易策略遍地开花,但是基于强化学习的市场模拟环境少之又少。像 OpenAI Gym 为 Atari 游戏专门搭建了RL环境,我们也需要构建不同金融市场的RL环境。
因此,FinRL-Meta应运而生。
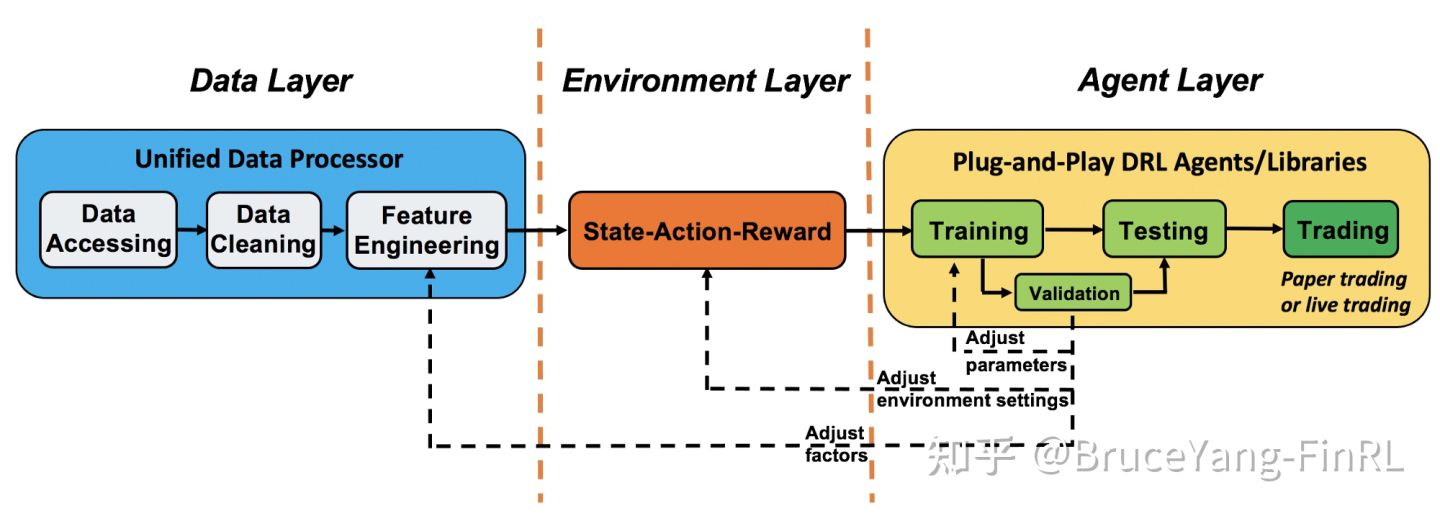
FinRL-Meta 框架为基于数据驱动的金融强化学习构建了市场模拟环境。
- FinRL-Meta 将金融数据处理与RL的策略的设计pipeline分离,并为金融大数据提供了Open-Source数据工程工具。
- FinRL-Meta 为各种交易策略提供了数百种市场模拟环境。
- FinRL-Meta 通过利用数千个 GPU 内核实现多处理模拟和训练。
FinRL-Meta 是一个三层架构:数据层、环境层和代理层。每一层相对独立。同时,各层通过端到端的接口交互,实现算法交易的完整工作流程。这种特殊的结构实现了 FinRL-Meta 的可扩展性(extensibility)。对于层内的更新和替代,这种结构最大限度地减少了对整个系统的影响。此外,用户自定义函数易于扩展,算法可以快速更新以保持高性能。
DataOps理念
DataOps 是一系列提高数据科学质量和缩短开发周期的原则和实践。它继承了敏捷开发(Agile)、DevOps 和精益制造(Lean manufacturing)的思想,并将其应用于数据科学和机器学习领域。
许多公司和机构已经开发了许多基于DataOps的应用,以提高数据科学、分析和机器学习任务的质量和效率。 然而,DataOps的方法论尚未应用于量化金融领域的强化学习研究。大多数金融强化学习的研究人员下载数据、清洗数据、提取因子都是case by case,手工工作量极大,数据质量可能无法保证。
FinRL-Meta在数据层遵循了DataOps范式。
- 建立了一套标准的金融数据工程pipeline,确保来自不同来源的不同格式的数据可以合并到一个统一的框架中。
- 使用了统一的数据处理器(unified data processor),它可以高质量和高效地下载数据、清理数据并从各种数据源中提取特征。FinRL-Meta的数据层提供了模型部署的敏捷性。
- FinRL-Meta采用了“训练-测试-交易流程”(training-testing-trading pipeline)。 DRL agents首先从训练环境中学习,然后在验证环境中进行验证和调参。然后在历史数据集中进行回测。最后,经过回测的DRL agents将部署在paper trading或实时交易市场中。首先,这个"训练-测试-交易流程"解决了信息泄露问题,因为在调整DRL agents时交易数据永远不会泄露。其次,统一的pipeline可以允许不同算法和策略之间进行公平比较。
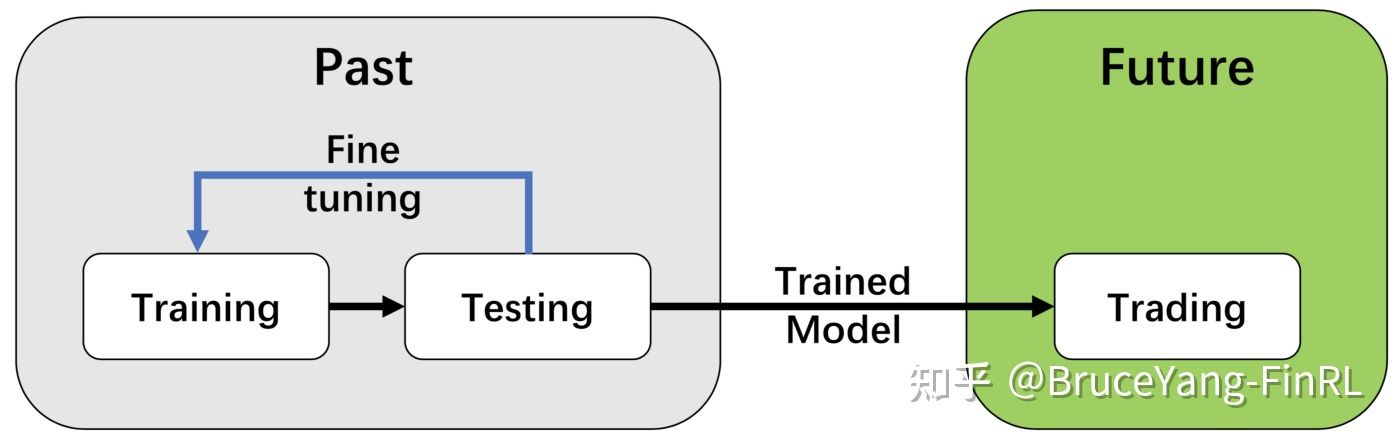
Unified Data Processor
在数据层,我们使用统一的数据处理器来下载数据、清理数据和提取特征。目前支持的平台及其属性如下表所示(持续更新中):
我们连接不同平台的数据 API,并在 FinRL-Meta 数据处理器中统一它们。给定开始日期、结束日期、股票列表、时间频率等,用户可以访问来自各种来源的数据。
从不同的数据源检索到的原始数据通常格式各异,并且存在不同程度的错误或NaN数据(缺失数据),使得数据清洗非常耗时。在 FinRL-Meta 数据处理器中,我们自动化了数据清理过程。
特征工程是数据层的最后一部分。在这部分中,我们通过将 Stockstats 和 TA-Lib 库与我们的数据处理器连接来自动计算techical indicators。用户可以从 Stockstats 库中快速添加指标,或添加用户定义的功能。支持移动平均收敛散度(MACD)、相对强弱指数(RSI)、平均方向指数(ADX)、商品通道指数(CCI)等常用技术指标。用户还可以快速添加来自其他库的指标,或直接添加其他用户定义的功能。
FinRL-Meta性能测评基准
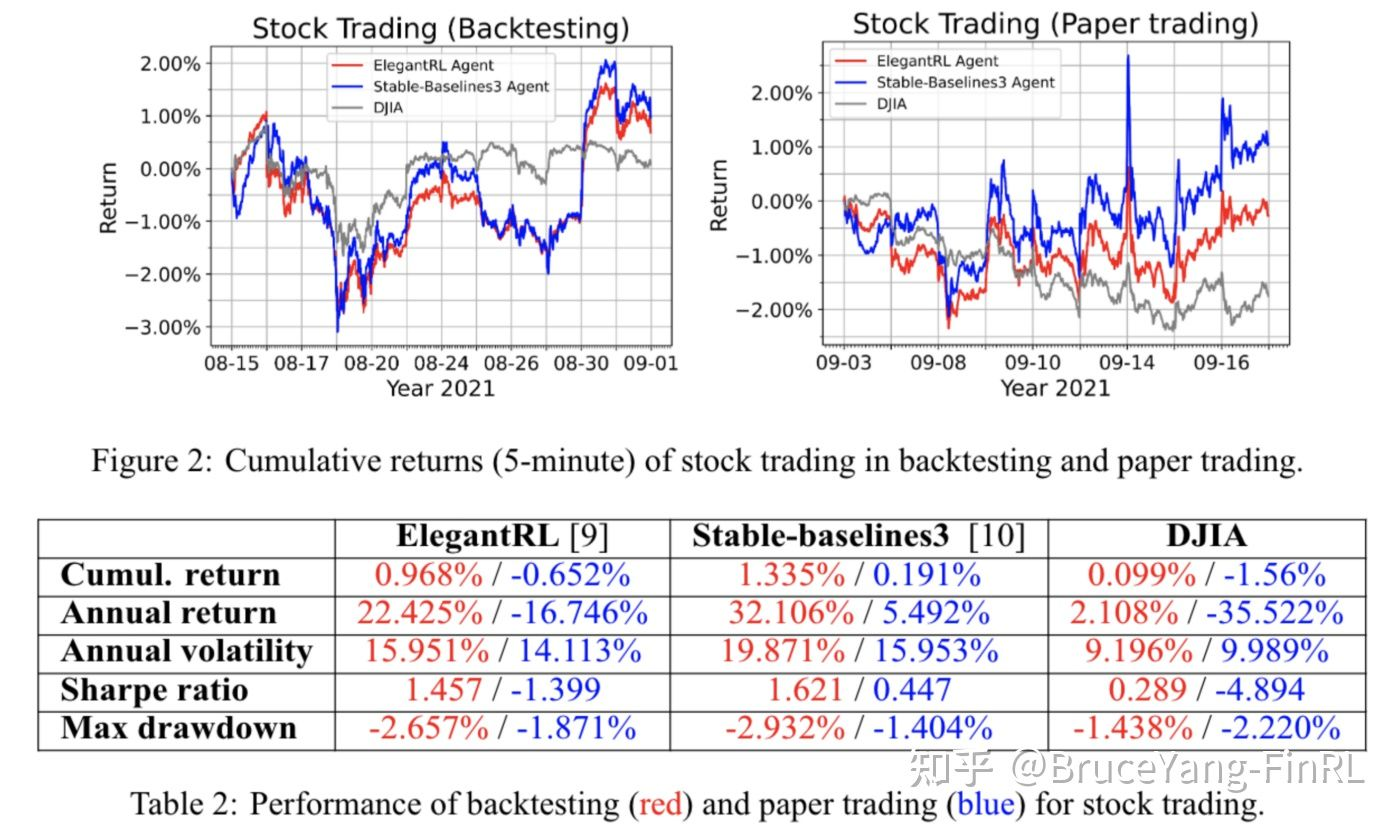
Stock Trading Task: 我们选择道琼斯工业平均指数 (DJIA) 中的 30 只成分股,在我们的测试期开始时访问。我们分别使用 ElegantRL、Stable-baselines3 和 RLlib 的PPO算法来训练Agents并使用 DJIA 指数作为基线。
- Backtesting:我们使用 06/01/2021 至 08/15/2021 的 1 分钟数据进行训练,使用 08/16/2021 至 08/31/2021 的数据进行验证(回测)。
- Paper Trading:然后我们使用 06/01/2021 到 08/31/2021 的数据重新训练代理,并从 09/03/2021 到 09/16/2021 进行纸面交易。从 Alpaca 的数据库和纸质交易 API 访问历史数据和实时数据。
在回测阶段(5 分钟内绘制),ElegantRL 代理和 Stable-baselines3 代理的年回报率和夏普比率均优于道指。 ElegantRL 代理实现了 22.425% 的年回报率和 1.457 的夏普比率。 Stable-baselines3 代理实现了 32.106% 的年回报率和 1.621 的夏普比率。在纸面交易阶段,结果与回测结果一致。 ElegantRL 代理和 Stable-baselines3 代理都优于基线。
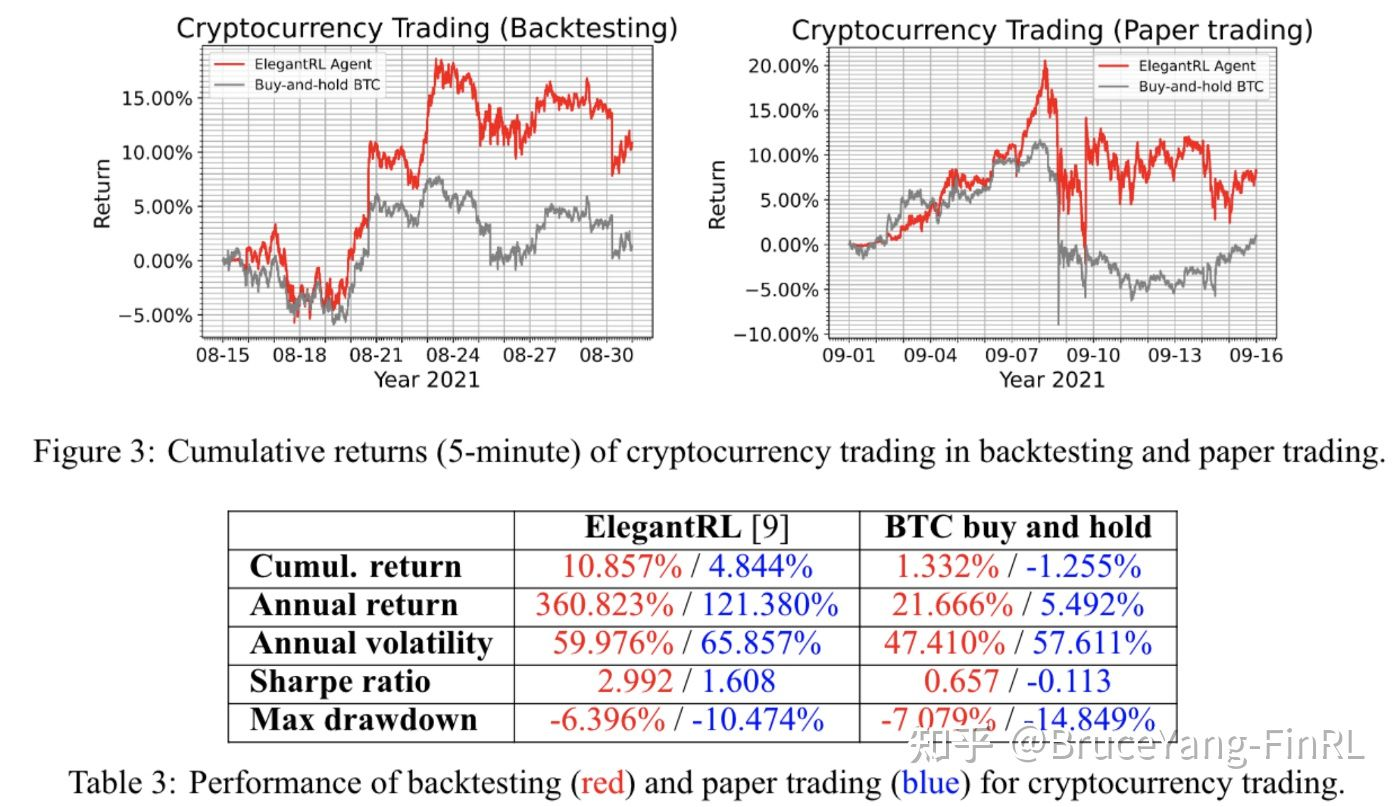
Cryptocurrency Trading Task: 我们选择市值排名前 10 的加密货币,截至 2021 年 10 月,市值排名前 10 的加密货币是:比特币 (BTC)、以太坊 (ETH)、卡尔达诺 (ADA)、币安币 (BNB)、瑞波币 (XRP)、索拉纳 (SOL) 、Polkadot (DOT)、Dogecoin (DOGE)、Avalanche (AVAX)、Uniswap (UNI)。我们使用 ElegantRL 的 PPO 算法来训练代理并使用比特币 (BTC) 价格作为基准。
- Backtesting:我们使用 06/01/2021 至 08/14/2021 的 5 分钟数据进行训练,使用 08/15/2021 至 08/31/2021 的数据进行验证(回测)。
- Paper Trading:然后我们使用 06/01/2021 至 08/31/2021 的数据重新训练代理,并从 09/01/2021 至 09/15/2021 进行纸面交易。历史数据和实时数据从币安(Binance)访问。
在回测阶段(5 分钟内绘制),ElegantRL 代理在大多数性能指标上都优于基准(BTC 价格)。它实现了 360.823% 的年回报率和 2.992 的夏普比率。 ElegantRL 代理在纸面交易阶段也跑赢了基准(BTC 价格),这与回测结果一致。
Conclusions
在本文中,我们遵循 DataOps 范式并开发了 FinRL-Meta 框架。 FinRL-Meta 提供开源数据工程工具和数百个模拟的市场环境。
对于未来的工作,我们计划构建一个基于多agents的市场模拟器,该模拟器由超过一万个agents组成,基于FinRL-Meta。首先,FinRL-Meta 旨在构建一个强化学习金融元宇宙,例如 Xland 环境和DeepMind 的行星尺度气候预测。为了提高大规模市场的性能,我们将采用基于 GPU 的大规模并行模拟类似于Isaac Gym。此外,探索深度进化 RL 框架来模拟市场也会很有趣。我们的最终目标是通过 FinRL-Meta 深入了解复杂的市场现象并为金融监管提供指导。
开源库
本文基于我们的论文:FinRL-Meta: Data-Driven Deep Reinforcement Learning in Quantitative Finance,该论文在 NeurIPS Workshop on Data-Centric AI 上发表。
感谢,哥伦比亚大学电子工程系-刘小洋博士后,香港大学-芮靖洋,知乎强化学习大佬-曾伊言,粤港澳大湾区数字经济研究院(IDEA)AI金融与深度学习负责人-郭健老师,西北大学副教授-汪昭然老师,上海纽约大学副教授-王丹老师对FinRL-Meta的贡献。