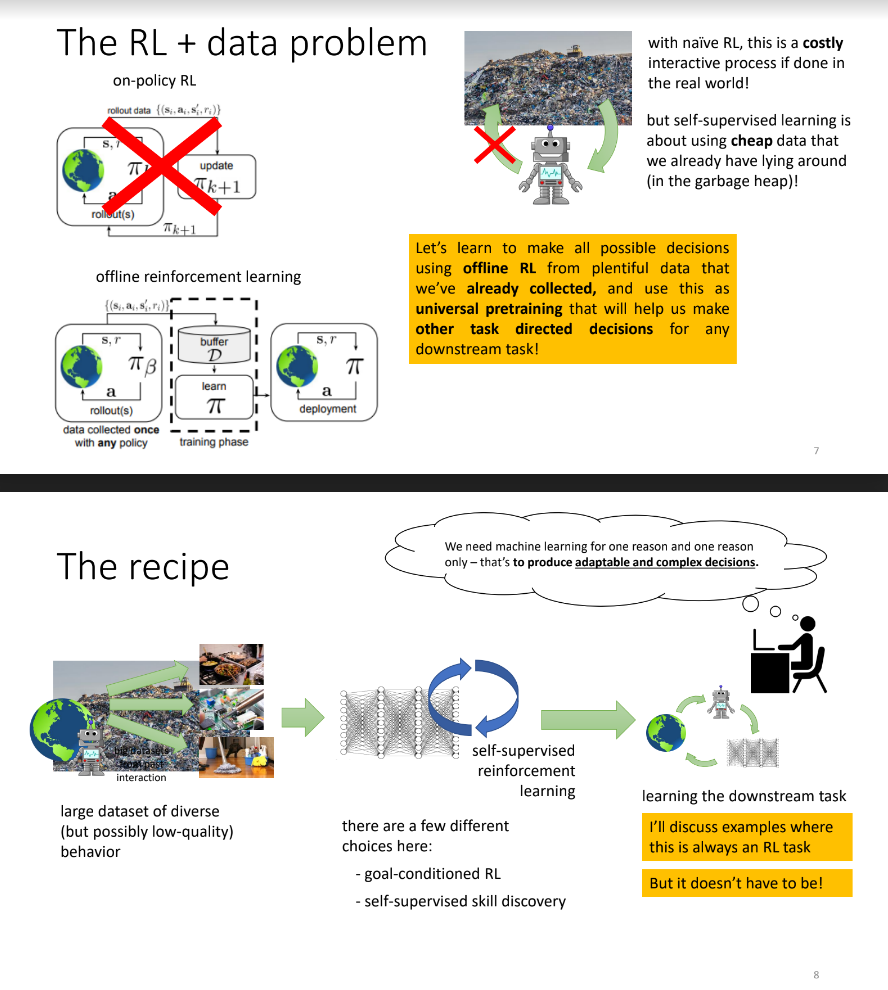
机器学习研究的最新历史告诉我们,当机器学习方法提供非常大、高容量的模型并在非常大且多样化的数据集上进行训练时,它们可能是最有效的。这促使社区寻找消除任何扩展瓶颈的方法。通常这些瓶颈中最重要的是需要人力,包括管理和标记数据集的工作。因此,近年来,人们相当重视利用可以大量收集的未标记数据。然而,一些最广泛使用的对此类未标记数据进行训练的方法本身需要人工设计的目标函数,这些目标函数必须以某种有意义的方式与下游任务相关联。我将争辩说,可以从强化学习中获得一个通用的、有原则的、强大的框架来利用未标记的数据,使用通用的无监督或自监督强化学习目标与可以利用大型数据集的离线强化学习方法相结合。我将讨论这样一个程序如何与潜在的下游任务更紧密地结合在一起,以及它如何建立在近年来开发的现有技术的基础上。
油管视频:https://www.youtube.com/watch?v=2jp3M3sj2aM
Arxiv: https://arxiv.org/pdf/2110.12543.pdf