一种基于强化学习的联邦学习算法:
AutoFL(AutoFL: Enabling Heterogeneity-Aware Energy Efficient Federated Learning)
AutoFL:实现异质性感知能源的高效FL方法
ABSTRACT 摘要
联邦学习这种分散的培训方法被证明是一种减少隐私泄露风险的实用解决方案。
由于非IID训练数据分布、广泛的系统异构性和现场随机变化的运行时效应,在边缘实现高效的FL部署具有挑战性。
通过定制一种强化学习算法来提出AutoFL,该算法在存在随机运行时方差、系统和数据异构性的情况下,学习并确定每个FL模型聚集了哪些K个参与设备和每个设备的执行目标。
1 INTRODUCTION
- 背景
最近,联合学习(FL)使智能手机能够协作训练共享ML模型,同时将所有原始数据保存在设备上。这种分散的方法是在训练深度神经网络(DNN)时降低隐私泄露风险的一种实用方法,因为只有模型梯度-而不是单个数据样本-才会上云来更新共享模型。
虽然FL在隐私敏感任务(包括情感学习、下一词预测、健康监测和项目排名方面表现出了巨大的潜力,但它的部署仍处于初级阶段。
2. 常见算法
FedAvg被认为是事实上的FL算法。FedAvg使用小批量大小为 ![[公式]](https://www.zhihu.com/equation?tex=B) 的随机梯度下降(SGD)在
的随机梯度下降(SGD)在 ![[公式]](https://www.zhihu.com/equation?tex=K) 个选定设备上训练
个选定设备上训练 ![[公式]](https://www.zhihu.com/equation?tex=E) 个epoch的模型,其中 是参与FL的
个epoch的模型,其中 是参与FL的 ![[公式]](https://www.zhihu.com/equation?tex=N) 个设备的小子集。(这里和上一篇FL开山文章的字母定义不同)然后 个设备将各自的模型梯度上传到云。
个设备的小子集。(这里和上一篇FL开山文章的字母定义不同)然后 个设备将各自的模型梯度上传到云。
关键问题就是:(1)选取哪些个 个设备进行聚合;(2)在每个子设备的训练执行目标需要达到什么效果。
3. 系统异构性和随机运行时间差异
在边缘端,多种设备具备多种Soc,高度的系统异构性在参与FL的智能手机之间引入了不同的、潜在巨大的性能差距。这些因素导致了掉队的问题——每一轮聚合的训练时间都受到参与速度最慢的智能手机的限制。以前的几个工作建立在FedAvg之上,通过从每轮中排除掉队或允许来自掉队的部分更新。然而,这些方法牺牲了准确性。
4. 数据异构性
每个参与设备的训练数据的不同特征给有效的FL执行带来了额外的挑战。为了保证模型收敛,重要的是要确保训练数据在参与设备上独立且相同地分布(IID),然而实际并不是。
为了缓解数据异构性,以前的方法排除了非IID设备,使用预热模型,或者跨参与设备的子集共享数据。然而,没有人考虑到数据和系统的异构性与运行时间差异。
5. 本文所介绍算法
本文提出了一个基于学习的能量优化框架AutoFL,该框架选择 个参与者和执行目标来保证模型质量,同时最大化单个参与者(或所有参与者的集群)的能量效率。由于最优决策随神经网络特性、FL全局参数、参与设备的轮廓、局部训练样本的分布以及随机运行时间方差而变化,因此设计空间庞大且无法枚举。因此,我们设计了一种强化学习技术。
对于每一轮聚合,AutoFL都会观察设备的神经网络特性、FL全局参数和系统配置文件(包括干扰强度、网络稳定性和数据分布)。然后,它选择本轮次的参与者设备,并同时确定每个参与者的执行目标,以在满足训练精度要求的同时最大限度地提高能效。判决的结果被测量并反馈给AutoFL,使其能够持续学习和预测后续回合的近乎最佳的行动。
采用了200个移动设备,包括高性能、中等性能和低性能三大类,主要贡献如下:
2 BACKGROUND
2.1 Federated Learning(联邦学习)
为了提高ML训练的数据保密性,引入联邦学习,允许诸如智能手机等边缘设备协作训练共享ML模型,同时将所有用户数据本地保存在该设备上。
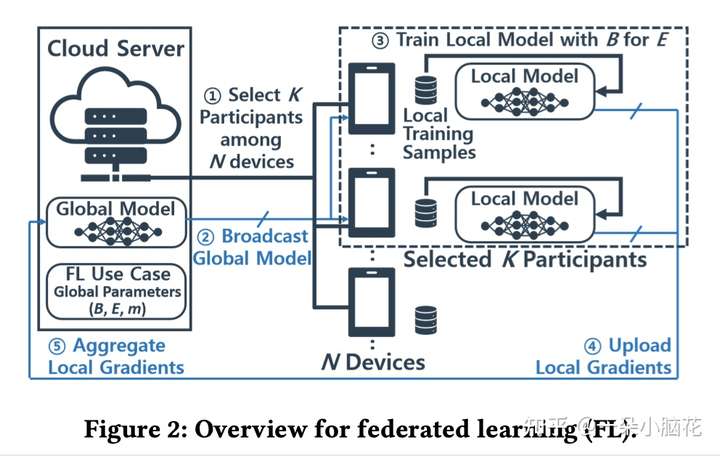
涉及参数:总设备 ,每次选择训练的设备个数 ,本地设备选择训练的部分数据 ,本地训练轮数
训练步骤:
服务器从 个设备中选择 个参与者;
将全局模型广播到所选择的设备;
每个参与者使用批大小为 的本地数据样本在 个epoch上独立地训练模型;
本地训练步骤完成,将计算出的模型梯度发送回服务器;
服务器聚集局部梯度并计算它们的平均值,更新全局模型。
2.2 Realistic Execution Environment(实际执行环境)
系统异构性、运行时间差异和数据异构性构成了FL的一个巨大的优化空间。
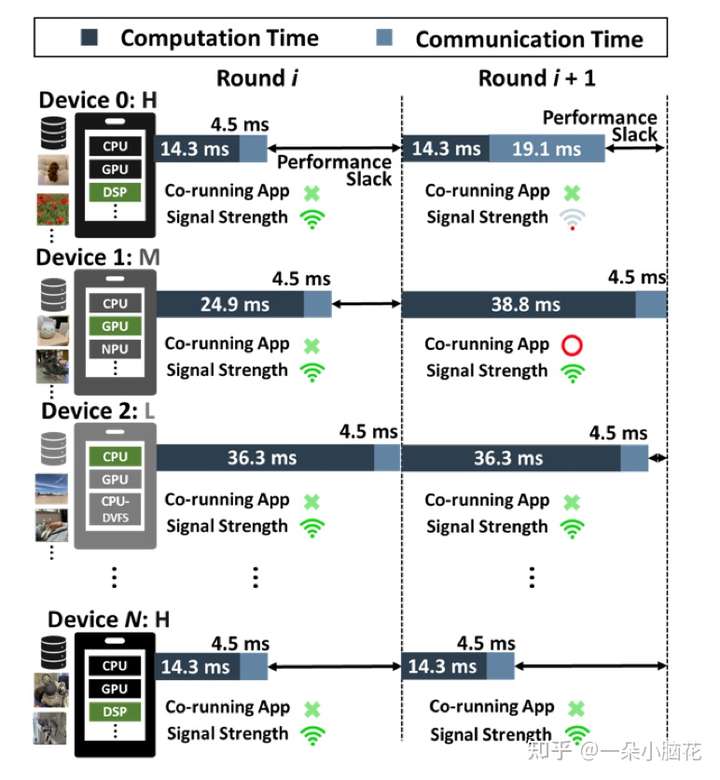
根据单个设备(即高端、中端或低端智能手机)的性能以及协处理器(如GPU、DSP或神经处理单元(NPU))的可用性,培训时间会有所不同。导致了掉队问题
图2:增加了一个新的job,会与联邦学习抢夺时间
每个设备性能不同,计算时间不同;
设备干扰不同(环境温度、网络信号强度),导致最终聚合时间高度动态;
最后,并非所有参与设备都拥有IID训练样本。
3 MOTIVATION(研究动机)
本节介绍FL的表征结果,主要考虑:能效、收敛时间和精确度。
3.1 Impact of FL Global Parameters and NN Characteristics(FL全局函数和神经网络特性的影响)
比较了4种不同FL全局参数设置,对应S1-S4,对CNN模型和MNIST数据集(CNN-MNIST)进行训练。定义了8种不同参与设备组合(C0-C7)上实现的能效,当全局参数设置从S1更改为S2、S3和S4时,最佳设备群集分别从C1更改为C2、C3和C4。
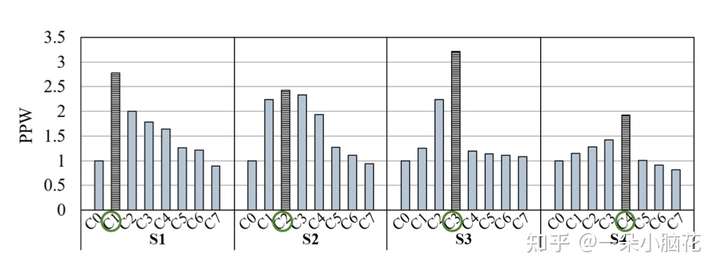
当分配给每个设备的计算数量较大(即S1)时,由于强大的CPU和协处理器以及更大的高速缓存和内存,具有更多数量的高端设备是有益的
当分配给每个设备的计算数量减少时(即从S1到S2和S3),它们的较低功耗(分别比高端设备低35.7%和46.4%)会抵消性能差距
如果K降低(即从S3到S4),减少高端设备的数量是有益的
对于计算莎士比亚数据集(LSTM模型)时,S1-S4上的最佳设备集群分别是C3、C4、C5和C5,原因:
CNN-MNIST:需要计算密集型Conv层和FC层,具有更强大移动SoC的高端设备比中低端设备表现出更好的性能和能效。
LSTM:由于内存操作,设备之间的性能差异减小,中低端设备的低功耗弥补了它们的性能损失。
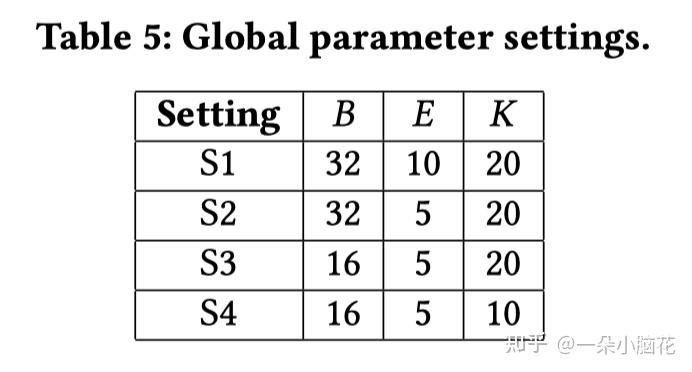
3.2 Impact of Runtime Variance(运行时间差异的影响)
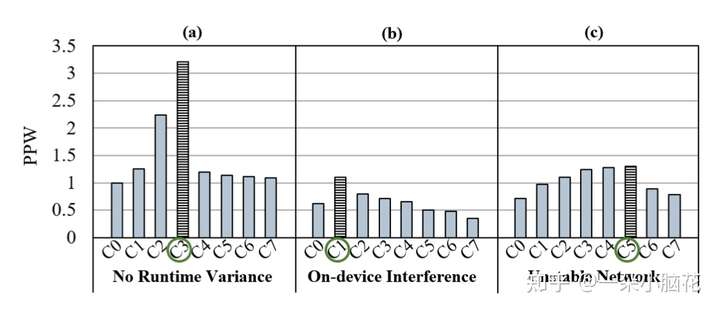
(a):无干扰和网络信号稳定
(b):存在设备上干扰时
(c):网络信号强度较弱时
直观地,在设备上存在干扰时,选择高端设备参与FL更有利,高端设备具有较高的计算和存储能力;
网络信号强度较差时,各设备上的通信时间和能量显著增加,不同类型设备之间的性能差距的影响会减小,故低端设备会更好。
3.3 Impact of Data Heterogeneity(数据异质性影响)
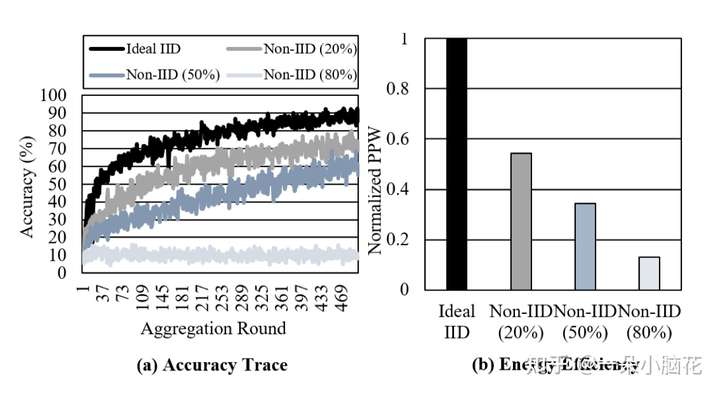
Non-IID数据比例越多,准确性越低,收敛时间显著增加。收敛时间的增加最终会降低FL的能量效率。
4 AUTOFL
在FL的背景下,给定一个NN和相应的全局参数,AutoFL学习在每个聚集轮中为每个参与者选择一个近似最优的聚类和一个节能的执行目标。
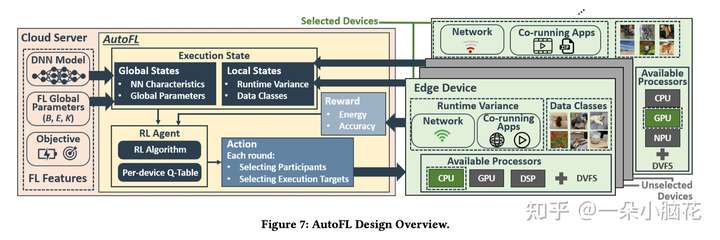
在每个FL聚合轮中,AutoFL观察FL的全局配置,包括目标NN和全局参数。还收集参与者设备的执行状态,包括它们的资源使用情况和网络稳定性,以及每个设备拥有的数据类的数量。
AutoFL识别当前的执行状态,选择参与者设备,提高能源效率和精度要求。
选择是基于每个设备的查找表(即q表),其中包含先前选择的累积奖励。
最后,它使用计算出的奖励更新每个设备的Q表。
高精度预测
要处理FL的动态执行环境,重要的是在现实环境中对核心组件--状态、动作和奖励--进行建模,同时注意要避免局部最优。
如果探索所有可能动作,RL收敛时间会过长,故采用 ![[公式]](https://www.zhihu.com/equation?tex=%5Cepsilon) -贪婪算法。
-贪婪算法。
AutoFL加速RL培训通过使设备在同一性能类别共享学习结果,从而最小化设备上RL的时间和能量开销。为了减小时间,Q-Learning适合作为RL训练方法。
为了允许大量的参与者,AutoFL可以为同一性能类别的设备开发一个共享的q表,但以预测精度的小损失为代价。
4.1 AutoFL Reinforcement Learning Design(强化学习设计)
核心组件:状态、动作、奖励
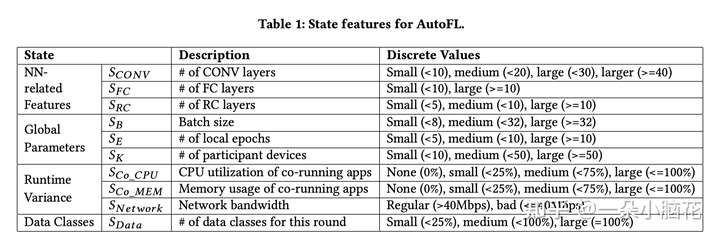
![[公式]](https://www.zhihu.com/equation?tex=S_%7BCONV%7D) 、
、 ![[公式]](https://www.zhihu.com/equation?tex=S_%7BFC%7D) 、
、 ![[公式]](https://www.zhihu.com/equation?tex=S_%7BRC%7D) 用来表示CONV、FC、RC层的数量;
用来表示CONV、FC、RC层的数量;
![[公式]](https://www.zhihu.com/equation?tex=S_B) 、
、 ![[公式]](https://www.zhihu.com/equation?tex=S_E) 、
、 ![[公式]](https://www.zhihu.com/equation?tex=S_K) 表示批次、训练次数、数据划分;
表示批次、训练次数、数据划分;
![[公式]](https://www.zhihu.com/equation?tex=S_%7BCo-CPU%7D) 、
、 ![[公式]](https://www.zhihu.com/equation?tex=S_%7BCo-MEM%7D) 表示CPU使用率和内存使用率;
表示CPU使用率和内存使用率;
![[公式]](https://www.zhihu.com/equation?tex=S_%7BNetwork%7D) 表示网络不稳定性建模;
表示网络不稳定性建模;
![[公式]](https://www.zhihu.com/equation?tex=S_%7BData%7D) 表示每个设备在聚合中拥有的数据类别数。
表示每个设备在聚合中拥有的数据类别数。
Q-Learning很难处理连续的数据,故采用DBSCAN将数据变为离散的(表中最后一列)。
动作分为两个层次:
全局角度:参与设备的选择为一个动作
选定设备:设备上选择执行目标(CPU、GPU或DSP)为另一个操作。
奖励
主要为三种奖励:
![[公式]](https://www.zhihu.com/equation?tex=R_%7Benergy-local%7D) :每个单独设备的估计能耗;
:每个单独设备的估计能耗;
![[公式]](https://www.zhihu.com/equation?tex=R_%7Benergy-global%7D) :所有设备的能耗估计值;
:所有设备的能耗估计值;
![[公式]](https://www.zhihu.com/equation?tex=R_%7Baccuracy%7D) :NN的测试精度。
:NN的测试精度。
需要先计算“计算能量” ![[公式]](https://www.zhihu.com/equation?tex=E_%7Bcomp%7D) ,如下,其中
,如下,其中 ![[公式]](https://www.zhihu.com/equation?tex=E_%7Bcore%7D%5Ei) 是第
是第 ![[公式]](https://www.zhihu.com/equation?tex=i) 个核所消耗能量,
个核所消耗能量, ![[公式]](https://www.zhihu.com/equation?tex=t_%7Bbusy%7D%5Ef) 是频率
是频率 ![[公式]](https://www.zhihu.com/equation?tex=f) 下繁忙状态,
下繁忙状态, ![[公式]](https://www.zhihu.com/equation?tex=P_%7Bbusy%7D%5Ef) 是频率 下消耗能量,
是频率 下消耗能量, ![[公式]](https://www.zhihu.com/equation?tex=t_%7Bidle%7D) 是空闲时间。
是空闲时间。
![[公式]](https://www.zhihu.com/equation?tex=E_%7B%5Ctext+%7Bcomp+%7D%7D%3D%5Csum_%7Bi%7D+E_%7Bc+o+r+e%7D%5E%7Bi%7D%5C%5C+)
![[公式]](https://www.zhihu.com/equation?tex=E_%7B%5Ctext+%7Bcore+%7D%7D%3D%5Csum_%7Bf%7D%5Cleft%28P_%7Bb+u+s+y%7D%5E%7Bf%7D+%5Ctimes+t_%7Bb+u+s+y%7D%5E%7Bf%7D%5Cright%29%2BP_%7Bi+d+l+e%7D+%5Ctimes+t_%7Bi+d+l+e%7D%5C%5C+)
对于GPU来说,其计算能量为:
![[公式]](https://www.zhihu.com/equation?tex=E_%7B%5Ctext+%7Bcomp+%7D%7D%3D%5Csum_%7Bf%7D%5Cleft%28P_%7B%5Ctext+%7Bbusy+%7D%7D%5E%7Bf%7D+%5Ctimes+t_%7B%5Ctext+%7Bbusy+%7D%7D%5E%7Bf%7D%5Cright%29%2BP_%7B%5Ctext+%7Bidle+%7D%7D+%5Ctimes+t_%7B%5Ctext+%7Bidle+%7D%7D%5C%5C+)
计算完计算能量后。计算其“通讯能量”,其中 ![[公式]](https://www.zhihu.com/equation?tex=t_%7BTX%7D) 是发送梯度更新时测量的等待时间,
是发送梯度更新时测量的等待时间, ![[公式]](https://www.zhihu.com/equation?tex=P_%7BTX%7D%5ES) 在信号强度为
在信号强度为 ![[公式]](https://www.zhihu.com/equation?tex=S) 的情况下,设备在 期间消耗的功率:
的情况下,设备在 期间消耗的功率:
![[公式]](https://www.zhihu.com/equation?tex=E_%7B%5Ctext+%7Bcomm+%7D%7D%3DP_%7BT+X%7D%5E%7BS%7D+%5Ctimes+t_%7BT+X%7D%5C%5C+)
同时,还计算非选定设备的“空闲能量”,其中 ![[公式]](https://www.zhihu.com/equation?tex=t_%7Bround%7D) 是训练轮次消费的时间:
是训练轮次消费的时间:
![[公式]](https://www.zhihu.com/equation?tex=E_%7Bi+d+l+e%7D%3DP_%7Bi+d+l+e%7D+%5Ctimes+t_%7B%5Ctext+%7Bround+%7D%7D%5C%5C+)
则每一台设备的 的计算如下,其中 ![[公式]](https://www.zhihu.com/equation?tex=S_t) 是一组选定的设备:
是一组选定的设备:
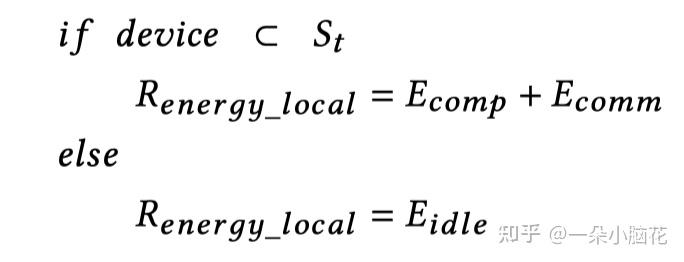
则 的计算为:
![[公式]](https://www.zhihu.com/equation?tex=R_%7Be+n+e+r+g+y_%7B-%7D%7Bg+l+o+b+a+l%7D%7D%3D%5Csum_%7Bi%7D%5E%7BN%7D+R_%7Be+n+e+r+g+y_%7B-%7D+l+o+c+a+l%7D%5C%5C+)
对于 其计算如下,其中 ![[公式]](https://www.zhihu.com/equation?tex=R_%7Baccuracy-prev%7D) 是上一轮训练神经网络的测试精度:
是上一轮训练神经网络的测试精度:

如果选择的动作不能提高上一轮的准确性,奖励是 ![[公式]](https://www.zhihu.com/equation?tex=R_%7Baccuracy%7D-100) (即准确度离100%有多远),以避免选择下一轮推理的动作。否则,将根据全局能量、局部能量、准确度和精确度提升量来计算每个设备的奖励。
(即准确度离100%有多远),以避免选择下一轮推理的动作。否则,将根据全局能量、局部能量、准确度和精确度提升量来计算每个设备的奖励。
4.2 AutoFL Implementation Detail(详细实施)
基于预先指定的探索概率,采用了具有均匀随机动作的ε-贪婪算法。对于其余部分,AutoFL会选择奖励最高的动作。
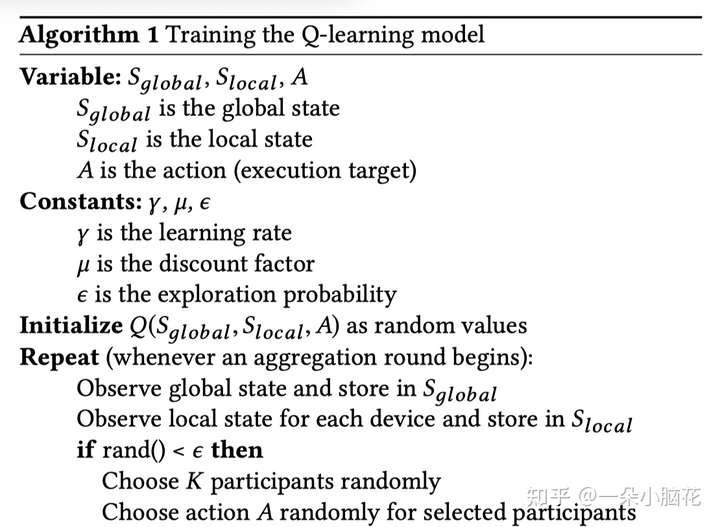

随机值初始化Q表
每个设备都具有一个Q表,autoFL使用每个设备的Q表来选择参与者和相应的A。在具有相同Q值的设备中,AutoFL随机选择参与者。
5 EXPERIMENTAL METHODOLOGY(实验方法论)
5.1 System Measurement Infrastructure(系统测量基础设施)
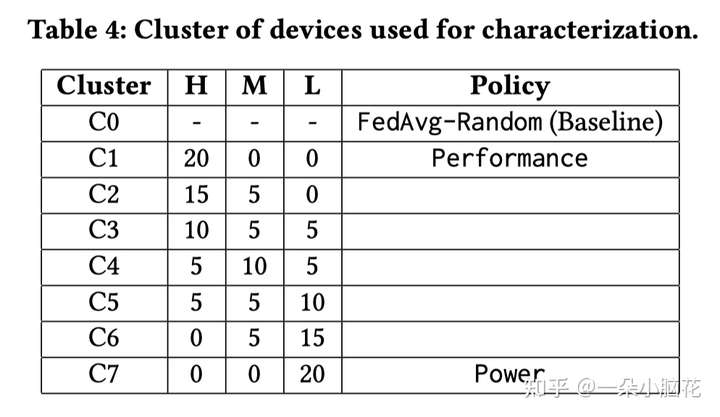
为了评估AutoFL的有效性,我们将其与其他五个设计点进行了比较:
FedAvg-Random:随机选择K个参与者
Power:最小化功率(即集合中的C7)
Performance:选择K个参与者以获得最佳时间性能的性能(即集合中的C1)
O_participant:K个参与者的最佳群集是通过考虑异质性和运行时方差来确定的
O_FL:考虑可用的设备上协处理器
5.2 Workloads and Execution Scenarios(工作负载和执行场景)
(1)用MNIST训练CNN;(2)用莎士比亚数据集训练LSTM;(3)用ImageNet数据集训练MobileNet模型,用于图像分类。
(1)在随机的设备子集上启动合成的共同运行应用程序,模仿真实应用程序的效果,合成应用按照观察到的网络浏览的使用模式生成CPU和存储器使用模式。
(2)通过调整网络延迟来模拟具有高斯分布的随机网络带宽。
M%的总设备具有非IID数据,而其余设备具有所有数据类别的IID样本。对于非IID设备,我们遵循狄利克莱分布随机分布每个数据类,浓度参数为0.1。浓度参数越小,每个类别集中在一类设备上越多。
5.3 AutoFL Design Specification(AutoFL设计规范)
定义了两级动作:
确定参与设备的集群
确定FL的执行目标
为了准确模拟FL执行的能效,我们测量了不同移动设备在不同频率步长下的功耗。
有两个超参数需要学习,学习率 ![[公式]](https://www.zhihu.com/equation?tex=%5Cgamma) 和折扣率
和折扣率 ![[公式]](https://www.zhihu.com/equation?tex=%5Cmu) ,经过对比实验,取学习率为0.9,折扣率为0.1
,经过对比实验,取学习率为0.9,折扣率为0.1
6 EVALUATION RESULTS AND ANALYSIS(评估结果和分析)
6.1 Result Overview(结果概述)
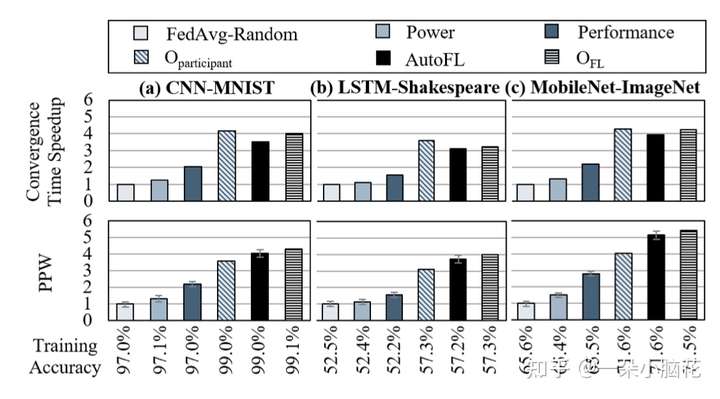
对5.1中提到的五个点进行对比,PPW为能耗比,CTS为收敛时间速度
AutoFL的能效收益来自于两个方面:
它可以在每个FL用例的大量类型中准确地识别出接近最佳的参与者,减少掉队者的性能松弛。
AutoFL为每个参与者确定了更节能的执行目标
带来的不足:收敛时间略长
6.2 Adaptability and Accuracy Analysis(适应性和准确性)
AutoFL提高了各种全局参数组合的能量效率和收敛时间
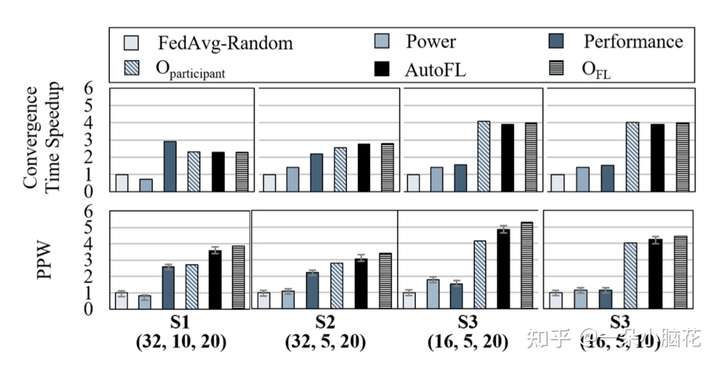
AutoFL试图准确地预测参与者设备的近最佳集群,而不考虑全局参数。因此,在能源效率和收敛时间方面,它总是超过FedAvg-Random、Performance和Power的基线设置。
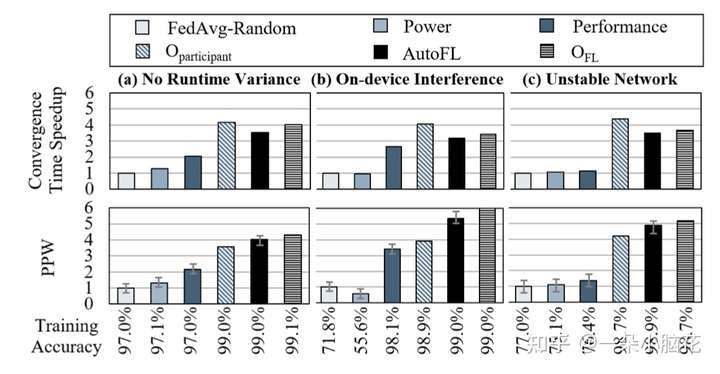
(a)当没有设备上的干扰时,(b)当有来自协同运行应用程序的设备上的干扰时,(c)当有网络方差时
由于设备上计算时间或通信时间的增加,每轮基线设置的训练时间显著增加。
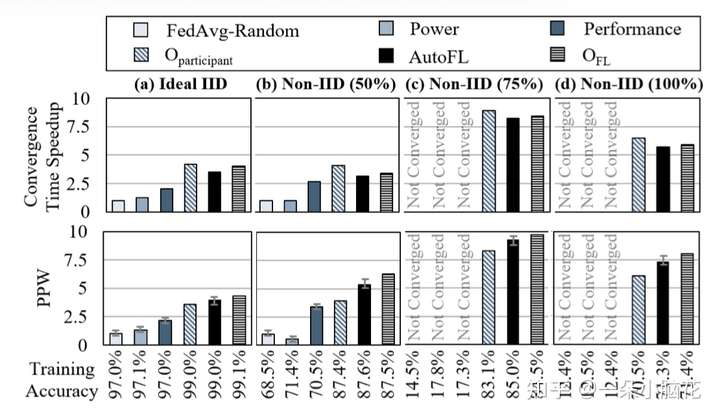
AutoFL动态学习数据异质性对收敛时间和能量效率的影响,适应不同设备之间不同的数据异质性水平。因此,即使在存在数据异质性的情况下,它也能达到接近最优的能源效率、收敛时间和模型质量。
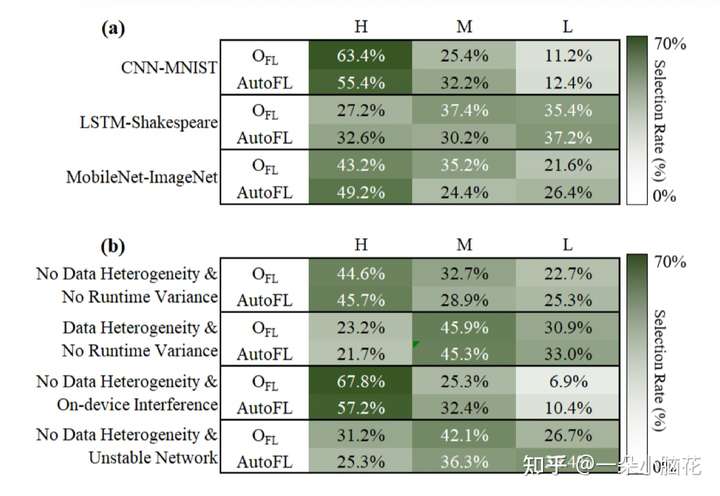
6.3 Comparison with Prior Work(与先前工作比较)
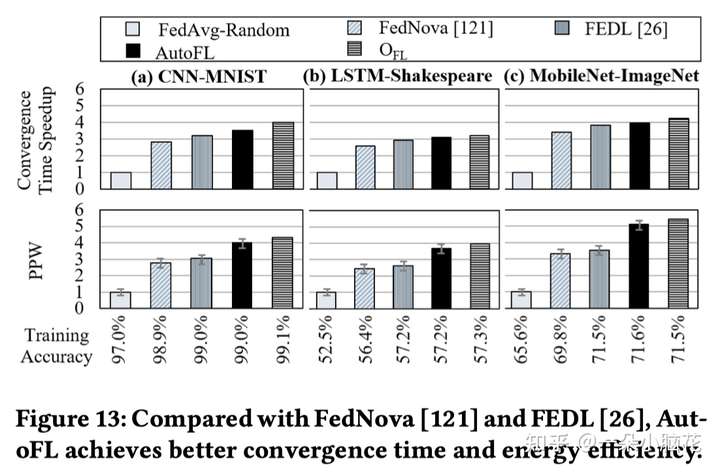
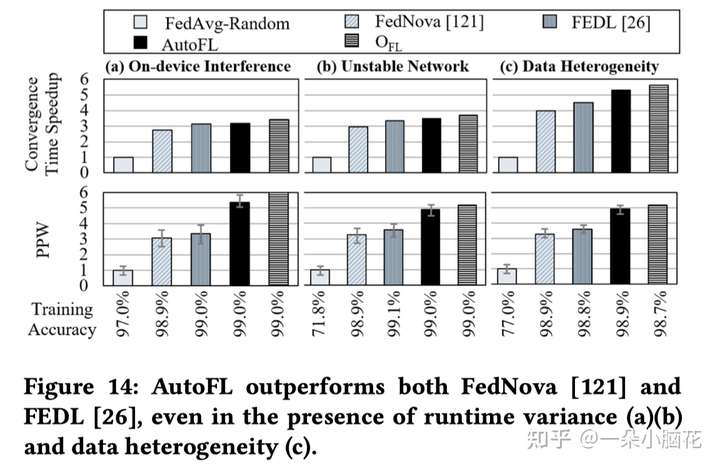
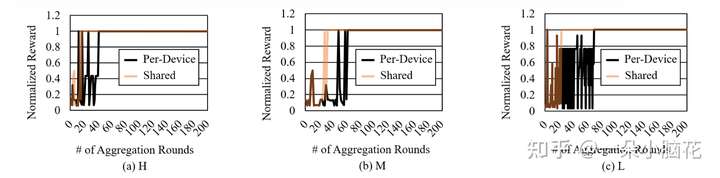
6.4 Overhead Analysis(开销分析)
当从头开始训练每个设备的Q表时,奖励平均在大约50-80轮聚合后收敛;FL收敛通常需要200多轮。
每个用户都经历了不同程度的运行时差异和数据异构性,但从各种设备学到的结果是相互补充的。
7 RELATED WORK(相关工作)
些先前的工作提出了统计模型来捕捉移动环境中的不确定性,以进行动态能源管理。但由于FL用例的高度分布式特性,以前的工作对于FL来说是次优的
每个聚集轮的训练时间受到最慢设备的限制。以前的工作排除掉队者,这些方法通常会牺牲准确性
数据异质性方面,以前的方法建议使用异步聚集算法排除来自非IID设备的更新,用全局共享数据的子集来预热全局模型,或者跨设备的子集共享数据。
FedProx:允许来自落后者和具有非IID训练数据分布的设备的部分更新来处理系统和数据异构性。