我想问一下在MADDPG训练时,平均reward为什么会出现这种反常的效果?
我使用的是OpenAI的multiagent-particle-envs-master环境,在simple_adversary即两绿一红抵达各自终点,防止对手离太近的环境。使用和论文一样的三层全连接网络,训练了20w次,以下是绿球的训练效果:
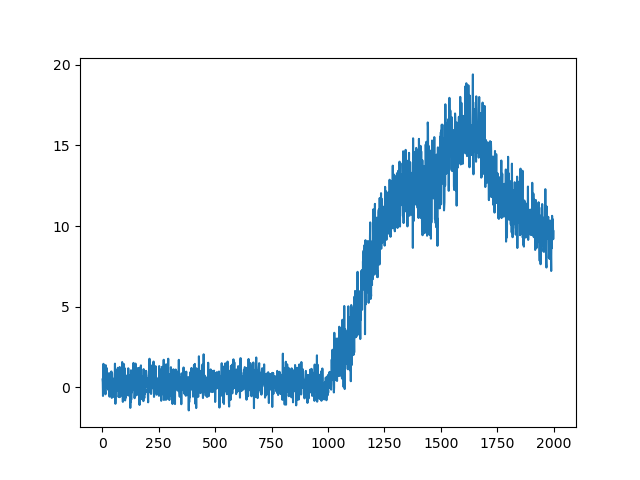
绿球的reward反常地先增后降,渲染的实际效果就是后期三个球朝三个不同的方向飞离,不管目标在哪,甚至离开目标前进,彼此之间没有任何追逐等动作。
actor和critic的学习率是1e-4和1e-5,折扣因子0.95,buffer是1e6,batch_size是256.
目前学习率,Buffer和batch全都修改过,都没有效果。
希望各路大神能指点迷津,感激不尽