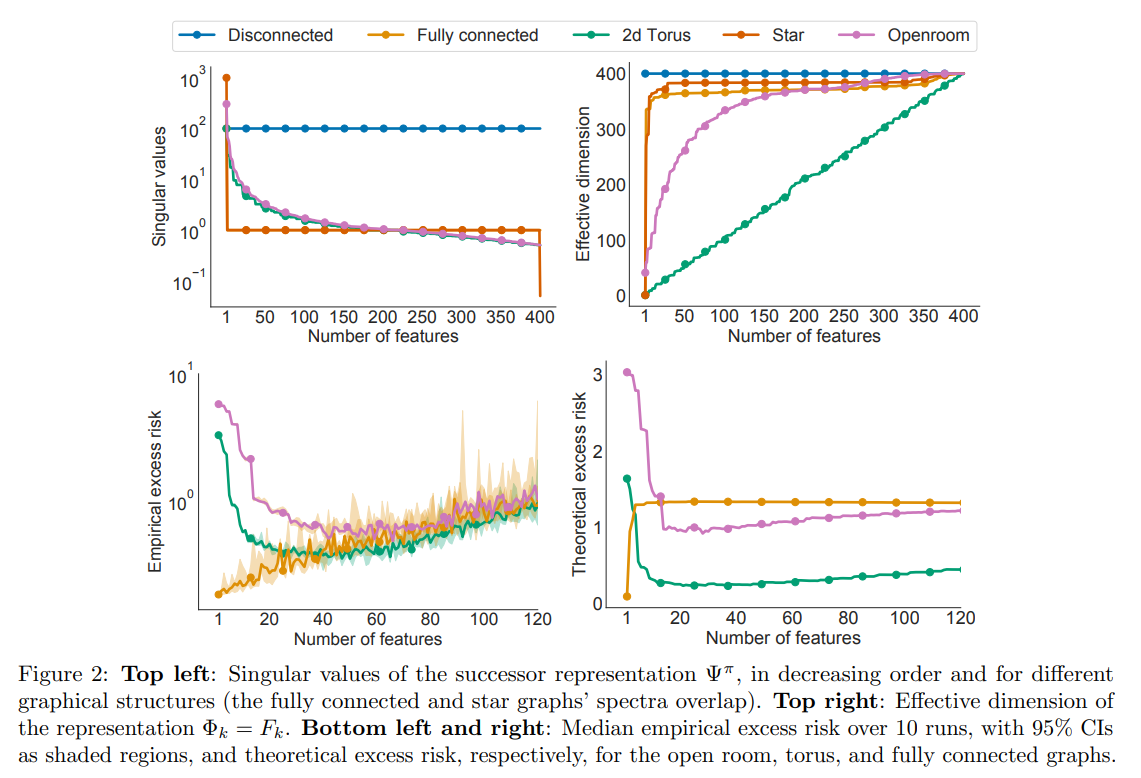
【译文】在强化学习中,状态表示用于处理大型问题空间。状态表示既可以用少量参数逼近价值函数,也可以泛化到新遇到的状态。它们的特征可以被隐式学习(作为神经网络的一部分)或显式学习(例如,Dayan (1993) 的后继表示)。虽然表示的近似属性已经得到了相当好的理解,但缺乏对这些表示如何以及何时泛化的精确表征。在这项工作中,我们解决了这一差距,并为由特定状态表示引起的泛化误差提供了一个信息界限。此界限基于有效维度的概念,该概念衡量了解一个状态的值对其他状态的值的了解程度。我们的界限适用于任何状态表示,并量化了泛化好的表示和近似好的表示之间的自然张力。我们通过对文献和街机学习环境结果中的经典表示学习方法的实证调查来补充我们的理论结果,并发现学习表示的泛化行为可以通过其有效维度得到很好的解释。
【原abstract】In reinforcement learning, state representations are used to tractably deal with large problem spaces. State representations serve both to approximate the value function with few parameters, but also to generalize to newly encountered states. Their features may be learned implicitly (as part of a neural network) or explicitly (for example, the successor representation of Dayan (1993)). While the approximation properties of representations are reasonably well-understood, a precise characterization of how and when these representations generalize is lacking. In this work, we address this gap and provide an informative bound on the generalization error arising from a specific state representation. This bound is based on the notion of effective dimension which measures the degree to which knowing the value at one state informs the value at other states. Our bound applies to any state representation and quantifies the natural tension between representations that generalize well and those that approximate well. We complement our theoretical results with an empirical survey of classic representation learning methods from the literature and results on the Arcade Learning Environment, and find that the generalization behaviour of learned representations is well-explained by their effective dimension.
原文链接: https://arxiv.org/pdf/2203.00543.pdf