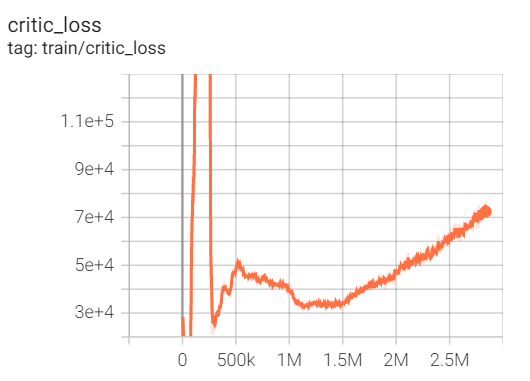
一开始用真实的股票数据,不收敛,毫无头绪。于是我把问题简化,自己用正弦函数+噪音生成股票数据,现在训练数据是50天,2个正弦周期,测试数据是一个正弦周期,收敛性仍旧不好,训练出来的AI像个傻子。我的state是[日期索引,现金,持仓,当日股票价格],有没有可能是state设计的有问题,导致无法训练成功,需要加入历史股票价格?一开始给的reward是相邻2个交易日的资产差,效果不太好,后面又改成只有最后一个交易给reward,具体值是赚了多少钱,其余交易日reward都是0,感觉稍微好了一点。reward有没有更好的设计?我的状态有6个float型,一个episode50帧,大概需要多大的模型就能保证过拟合,训练时间足够长。如果有一个足够大的模型,足够长的训练时间,是不是一定会过拟合?也就是loss为0.
我是在FinRL-Meta上跑的,TD3算法,下面是参数,改了好多遍了
DDPG_PARAMS = { "batch_size": 128, #一个批次训练的样本数量
"buffer_size": 100000, #每个看1000次,需要1亿次
"learning_rate": 0.0001,
"gamma": 0.9999,
"action_noise": "ornstein_uhlenbeck",
"gradient_steps": 100, # 一共训练多少个批次,1 - beta1 ** step
"policy_delay": 2, # critic训练多少次才训练actor一次
"train_freq": (500, "step"), # 采样多少次训练一次
"learning_starts": 10 }
POLICY_KWARGS = dict(net_arch=dict(pi=[64, 256, 256, 256, 64], qf=[64, 256, 256, 256, 64]), optimizer_kwargs=dict(weight_decay=0, amsgrad=False, betas=[0.9999, 0.9999]))
我现在是想过拟合而不可得 🤣 🤣