在过去的几年里,由于强化学习 (RL) 在游戏和机器人控制方面的高调成功,人们对强化学习(RL) 产生了浓厚的兴趣。然而,与监督学习方法不同,监督学习方法从收集一次然后重复使用的海量数据集中学习,RL 算法使用试错反馈循环,需要在学习期间进行主动交互,每次学习新策略时都会收集数据。这种方法在许多现实世界的环境中是令人望而却步的,例如医疗保健、自动驾驶和对话系统,在这些环境中,试错数据收集可能成本高昂、耗时甚至不负责任。即使是一些主动数据收集可以解决的问题使用时,交互式收集的要求限制了数据集的大小和多样性。
离线 RL(也称为批量RL 或完全脱离策略RL)仅依赖于先前收集的数据集,无需进一步交互。它提供了一种利用先前收集的数据集(来自先前的 RL 实验、人类演示和手工设计的探索策略)的方法,以便自动学习决策策略。原则上,虽然off-policy RL算法可以在离线设置(完全off-policy)中使用,但它们通常只有在与主动环境交互使用时才能成功——在没有收到这种直接反馈的情况下,它们在实践中往往表现出不理想的性能. 因此,虽然离线 RL 具有巨大的潜力,但如果不解决重大的算法挑战,就无法发挥这种潜力。
在“离线强化学习:关于开放问题的教程、评论和观点”中,我们提供了关于解决离线 RL 挑战的方法的综合教程,并讨论了仍然存在的许多问题。为了解决这些问题,我们设计并发布了一个开源基准测试框架,用于深度数据驱动的强化学习(D4RL)的数据集,以及一种新的、简单且高效的离线强化学习算法,称为保守 Q 学习( Conservative Q-learning)。 CQL)。
离线 RL 的基准
为了了解当前方法的能力并指导未来的进展,首先需要有有效的基准。先前工作中的一个常见选择是简单地使用由成功的在线 RL 运行生成的数据。然而,虽然简单,但这种数据收集方法是人为的,因为它涉及训练在线 RL 代理,正如我们之前讨论的那样,这在许多现实世界环境中是令人望而却步的。一个人希望从提供良好覆盖范围的各种数据源中学习一种比当前最好的策略更好的策略的任务。例如,有人可能从手动设计的机械臂控制器收集数据,并使用离线 RL 来训练改进的控制器。为了在现实环境下在这一领域取得进展,人们需要一个准确反映这些设置的基准套件,同时足够简单和易于访问以实现快速实验。
D4RL提供标准化环境、数据集和评估协议,以及最新算法的参考分数,以帮助实现这一目标。这是一个“包含电池”的资源,非常适合任何人加入并以最小的麻烦开始。
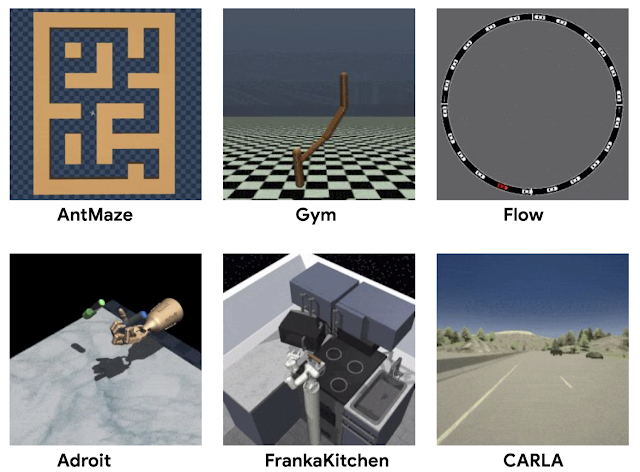 D4RL 中的环境
D4RL 中的环境
D4RL 的关键设计目标是开发既反映现实世界数据集挑战又反映现实世界应用程序的任务。以前的数据集使用从随机代理或使用 RL 训练的代理收集的数据。相反,通过思考自动驾驶、机器人技术和其他领域的潜在应用,我们考虑了离线 RL 的实际应用可能需要处理从人类演示或硬编码控制器生成的数据、从异构来源收集的数据以及数据由具有各种不同目标的代理收集。
除了广泛使用的MuJoCo运动任务之外,D4RL 还包括用于更复杂任务的数据集。例如,需要操纵逼真的机械手来使用锤子的Adroit 领域说明了在有限的人类演示中工作的挑战,如果没有这些任务,这些任务将极具挑战性。以前的工作发现现有数据集无法区分竞争方法,而 Adroit 域揭示了它们之间的明显缺陷。
现实世界任务的另一种常见场景是,用于训练的数据集是从执行与感兴趣任务相关但并非专门针对的其他活动的代理收集的。例如,来自人类驾驶员的数据可以说明如何很好地驾驶汽车,但不一定显示如何到达特定的期望目的地。在这种情况下,人们可能希望离线 RL 方法将驾驶数据集中的部分路线“缝合”在一起,以完成一项在数据中实际上没有看到的任务(即导航)。作为一个说明性示例,给定下图中标记为“A”和“B”的路径,离线 RL 应该能够“重新混合”它们以生成路径 C。
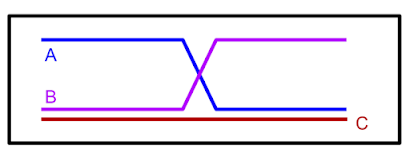 只有观察到的路径 A 和 B,它们可以组合形成最短路径 (C)。
只有观察到的路径 A 和 B,它们可以组合形成最短路径 (C)。
我们构建了一系列难度越来越大的任务来锻炼这种“拼接”能力。如下所示的迷宫环境需要两个机器人(一个简单的球或“蚂蚁”机器人)导航到一系列迷宫中的位置。
 D4RL 中的迷宫导航环境,需要“拼接”部分路径来完成数据集中没有的新导航目标。
D4RL 中的迷宫导航环境,需要“拼接”部分路径来完成数据集中没有的新导航目标。
Franka 厨房领域(基于Adept 环境)提供了一个更复杂的“拼接”场景,其中人类使用 VR 界面进行的演示包含一个多任务数据集,并且离线 RL 方法必须再次“重新混合”这些数据。
 “弗兰卡厨房”领域需要使用来自在模拟厨房中执行各种不同任务的人类演示者的数据。
“弗兰卡厨房”领域需要使用来自在模拟厨房中执行各种不同任务的人类演示者的数据。
最后,D4RL 包括两个任务,旨在更准确地反映离线 RL 的潜在现实应用,均基于现有的驾驶模拟器。一个是第一人称驾驶数据集,它利用英特尔开发的广泛使用的CARLA模拟器,在现实驾驶领域提供逼真的图像,另一个是来自Flow交通控制模拟器(来自加州大学伯克利分校)的数据集,它需要控制自动驾驶车辆以促进有效的交通流量。
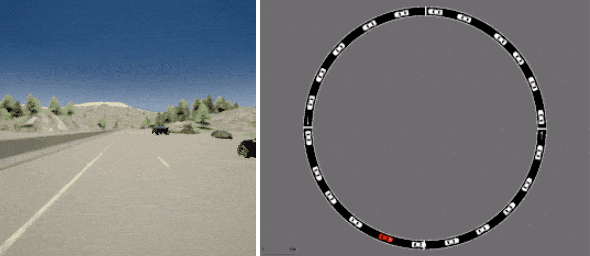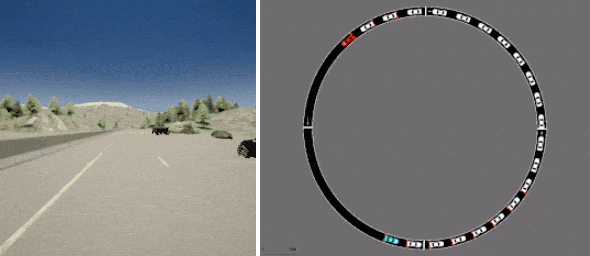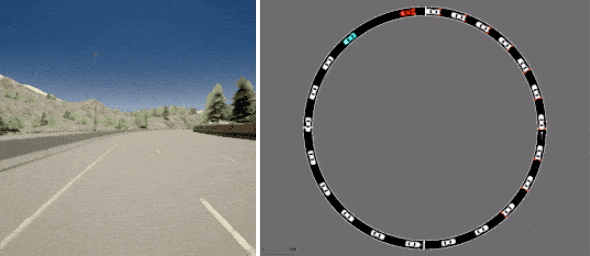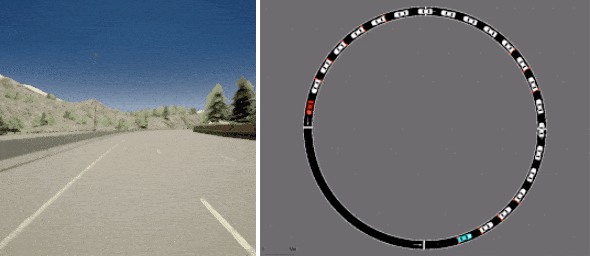 D4RL 包括基于现有现实模拟器的数据集,用于使用 CARLA(左)进行驾驶和使用 Flow(右)进行交通管理。
D4RL 包括基于现有现实模拟器的数据集,用于使用 CARLA(左)进行驾驶和使用 Flow(右)进行交通管理。
我们已将这些任务和标准化数据集打包到一个易于使用的Python 包中以加速研究。此外,我们使用相关的先前方法(BC、SAC、BEAR、BRAC、AWR、BCQ )为所有任务提供基准数字,以便为新方法提供基准。我们不是第一个提出离线 RL 基准的人:许多先前的工作已经提出了基于运行 RL 算法的简单数据集,以及最近的几个 作品提出了具有图像观察和其他特征的数据集。然而,我们相信 D4RL 中更真实的数据集组成使其成为推动该领域进步的有效方式。
离线 RL 的改进算法在
开发基准任务时,我们发现现有方法无法解决更具挑战性的任务。核心挑战来自分配转变:为了改进历史数据,离线 RL 算法必须学会做出与数据集中做出的决策不同的决策。然而,当一个看似好的决定的后果无法从数据中推断出来时,这可能会导致问题——如果没有智能体在迷宫中进行这个特定的转弯,那么人们怎么知道它是否会导致目标呢?如果不处理这种分布转移问题,离线 RL 方法可能会错误地推断,从而对罕见行动的结果做出过于乐观的结论。将此与在线设置进行对比,其中奖励奖金以好奇心和惊喜为模型乐观地偏向代理以探索所有潜在的奖励路径。因为代理接收到交互式反馈,所以如果该动作结果是没有回报的,那么它可以简单地避开未来的路径。
为了解决这个问题,我们开发了保守的 Q 学习(CQL),这是一种离线 RL 算法,旨在防止高估,同时避免显式构建单独的行为模型并且不使用重要性权重。虽然标准的 Q-learning(和 actor-critic)方法从先前的估计中引导,但 CQL 的独特之处在于它从根本上是一种悲观算法:它假设如果给定动作没有看到好的结果,那么该动作可能不会做个好人。CQL 的中心思想是学习策略预期回报的下限(称为Q 函数),而不是学习近似预期回报。如果我们然后在这个保守的 Q 函数下优化我们的策略,我们可以确信它的值不低于这个估计值,从而防止高估错误。
我们发现 CQL 在许多更难的 D4RL 任务上都获得了最先进的结果:CQL 在 AntMaze、Kitchen 任务和 8 个 Adroit 任务中的 6 个上优于其他方法。特别是在 AntMaze 任务中,需要使用“蚂蚁”机器人在迷宫中导航,CQL 通常是唯一能够学习非平凡策略的算法。CQL 在其他任务上也表现出色,包括 Atari 游戏。关于Agarwal 等人的 Atari 任务。,当数据有限(“1%”数据集)时,CQL 优于先前的方法。此外,CQL 易于在现有算法(例如QR-DQN和SAC)之上实现,无需训练额外的神经网络。
 使用Agarwal 等人的 1% 数据集在 Atari 游戏上的 CQL 性能。
使用Agarwal 等人的 1% 数据集在 Atari 游戏上的 CQL 性能。
未来的想法
我们对快速发展的离线 RL 领域感到兴奋。虽然我们朝着标准基准迈出了第一步,但显然仍有改进的空间。我们预计随着算法的改进,我们将需要重新评估基准测试中的任务并开发更具挑战性的任务。我们期待与社区合作以发展基准和评估协议。在一起,我们可以将离线 RL 的丰富承诺带到现实世界的应用程序中。
致谢
这项工作是与加州大学伯克利分校的博士生 Aviral Kumar、Justin Fu 和 Aurick Zhou 合作完成的,来自 Google Research 的 Ofir Nachum 也做出了贡献。