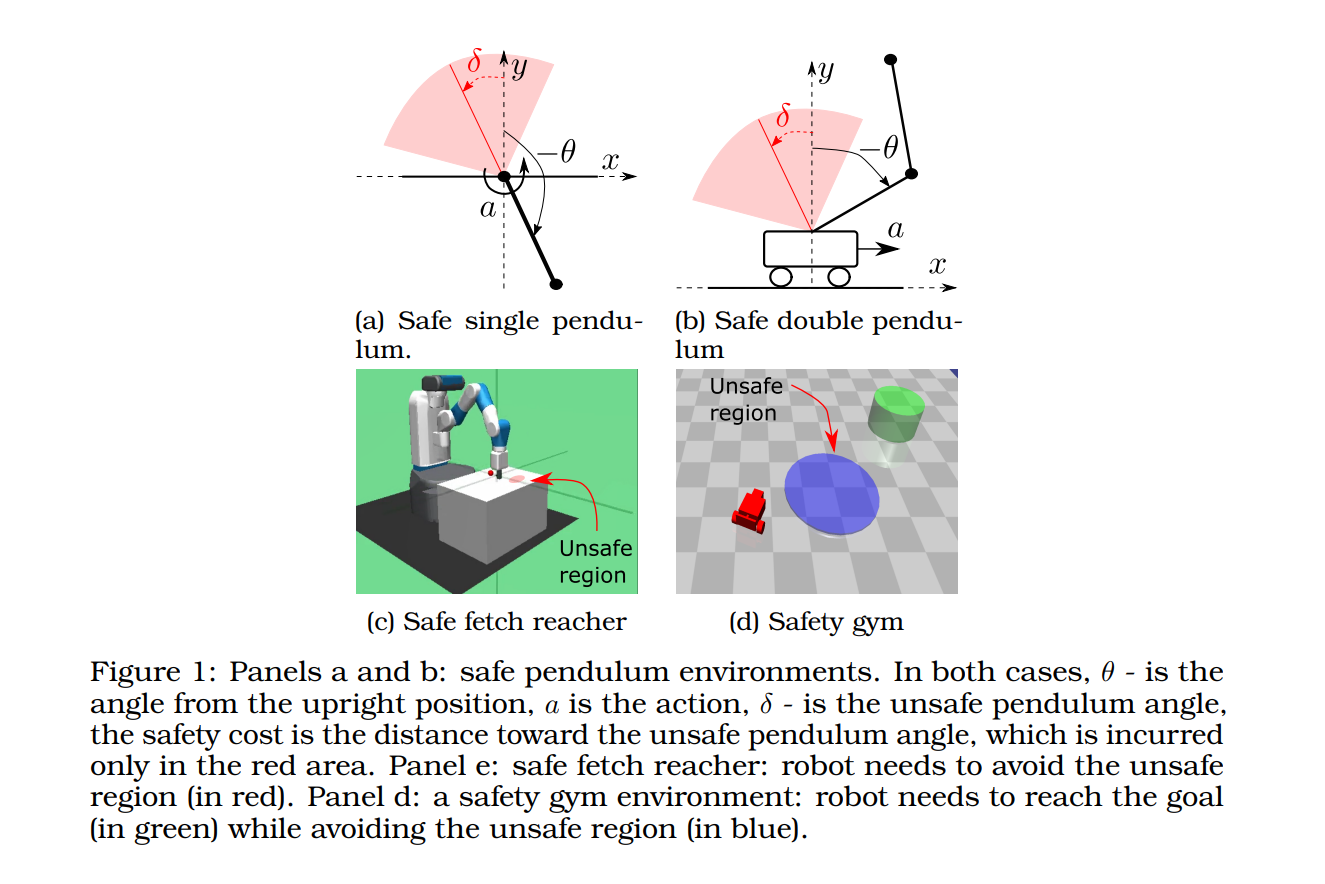
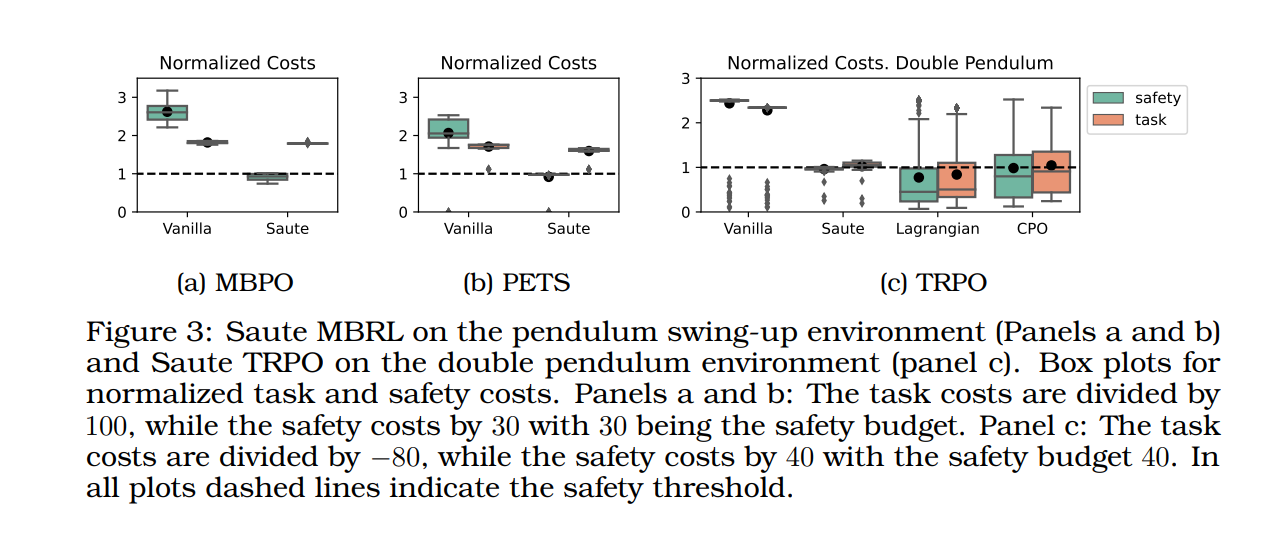
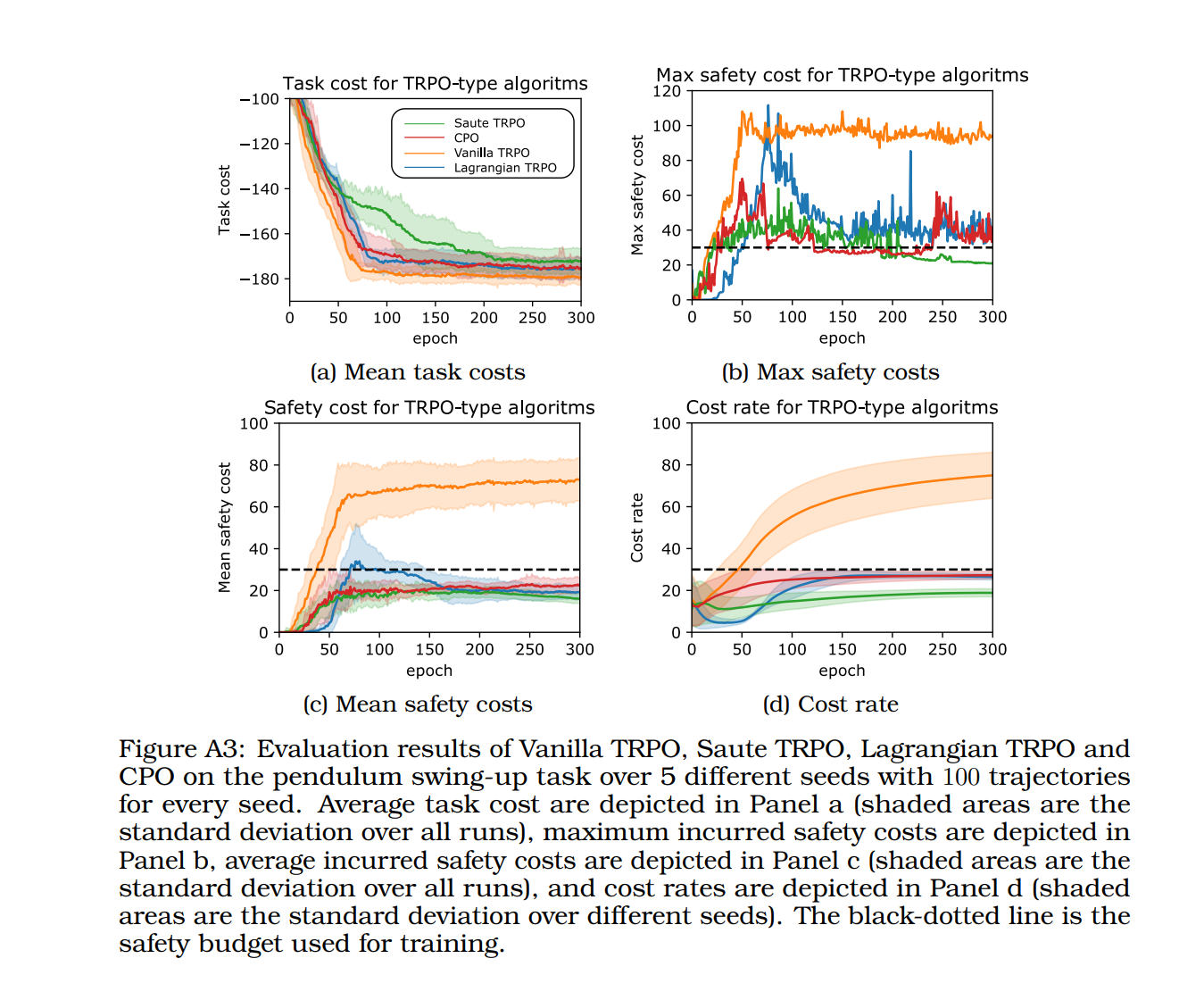
几乎肯定(或以概率为一)满足安全约束对于在现实应用中部署强化学习 (RL) 至关重要。例如,飞机着陆和起飞在理想情况下应该以概率 1 发生。我们通过引入安全增强(Saute)马尔可夫决策过程(MDP)来解决这个问题,其中通过将安全约束增强到状态空间并重塑目标来消除安全约束。我们证明了 Saute MDP 满足 Bellman 方程,并使我们更接近于解决几乎肯定满足约束的 Safe RL。我们认为 Saute MDP 允许从启用新功能的不同角度查看安全 RL 问题。例如,我们的方法具有即插即用的特性,即任何 RL 算法都可以“炒”。此外,状态增强允许跨安全约束的策略泛化。我们最终表明,当约束满足非常重要时,Saute RL 算法可以超越其最先进的算法。 PDF: https://arxiv.org/pdf/2202.06558.pdf Github: https://github.com/huawei-noah/HEBO/tree/master/SAUTE