OpenDILab新开设了混合动作空间专栏,将从离散动作空间和连续动作空间入手,为大家介绍混合动作空间的起源和发展,并解读一系列学术界相关paper。
本文作为混合动作空间系列专题文章的第一篇,主要是介绍混合动作空间的类型以及经典环境,公式不多,可以放心食用~
近年来,强化学习的混合动作空间(Hybrid Action Space) 逐渐成为热门话题。动作空间是强化学习问题里的一个重要设定。我们训练一个人工智能体,都离不开动作空间。
动作空间的重要性有以下两点,设计良好的动作空间,对于强化学习算法的训练非常重要:
1.处理不同的动作空间类型,需要采取不同的优化算法;
2.动作空间的复杂性也影响着RL算法的性能表现。
一个典型的强化学习环境通常是离散(Discrete) 或连续 (Continuous) 动作空间。有很多朋友对强化学习环境很感兴趣,想要深究钻研。
在此推荐下我们的强化学习平台DI-engine,平台介绍了目前强化学习领域各种经典的离散/连续/混合动作环境,也总结了各种RL算法所适用的动作空间类型。
✨DI-engine项目repo地址: https://github.com/opendilab/DI-engine
✨联系方式:
QQ群 700157520
欢迎大家多去参观交流提建议哦!

离散动作空间指动作的可取值是有限个离散的数值,比如

常见的解决离散动作空间的RL经典算法有 DQN(Human-level control through deep reinforcement learning)、A2C(Asynchronous Methods for Deep Reinforcement Learning) 等。
✨DQN介绍:
https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf
✨A2C介绍:
https://arxiv.org/pdf/1602.01783.pdf
例如,Atari是最经典最常用的离散动作空间强化学习环境,常作为离散动作空间强化学习算法的基准测试环境。
✨Atari详细指南:
https://di-engine-docs.readthedocs.io/zh_CN/latest/env_tutorial/atari_zh.html

Atari 强化学习环境

连续动作空间指动作的可取值是无限个连续的数值,比如
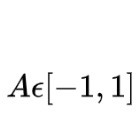
常见的解决连续动作空间的RL经典算法有 DDPG、ACER。
✨DDPG介绍:
https://arxiv.org/pdf/1509.02971.pdf
✨ACER介绍:
https://arxiv.org/pdf/1611.01224.pdf
例如,Mujoco环境就是最常见的连续动作空间环境之一。

Mujoco强化学习环境

混合动作空间在游戏的场景中非常常见。例如,王者荣耀手游的技能施放,选择技能1、技能2、技能3,这是离散动作;当确定一个技能后,选择技能的瞄准角度,这是连续动作。
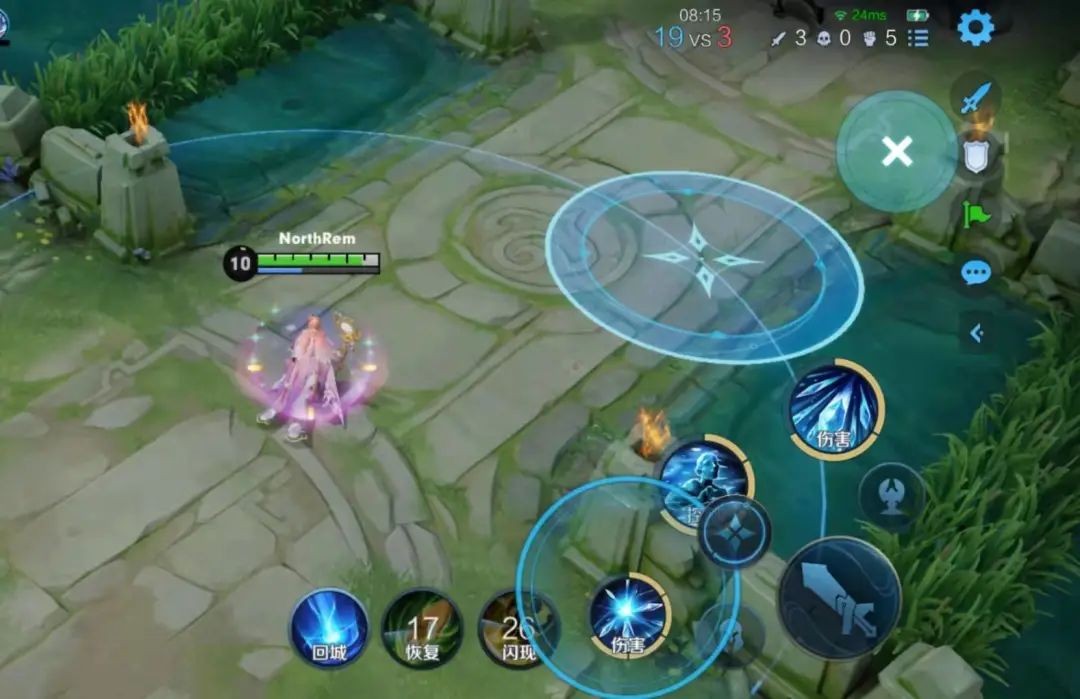
王者荣耀游戏环境
当然,这只是混合动作空间的一种类型。目前常见的混合动作空间有如下四种类型:
- Parameterized Action Space
- Multi-Discrete Action Space
- Multi-Binary Action Space
- Hierarchically Structured Action Space
🪐Parameterized Action Space:
Parameterized Action Space 的概念在这篇15年的paper《Deep reinforcement learning in parameterized action space》中被提出,也是目前最常见的混合动作空间类型。
✨paper链接:
https://arxiv.org/abs/1511.04143
Parameterized Action Space 的构成如下:
1. 首先,定义一个离散动作空间
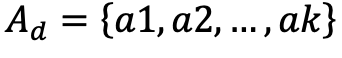
2. 对于每一个离散动作
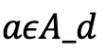 , 都有m_α个连续参数
, 都有m_α个连续参数
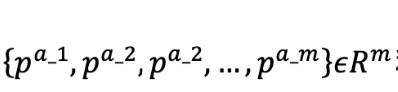 和它相连。
和它相连。
也就是说, 每一个动作由这样的tuple来表示:
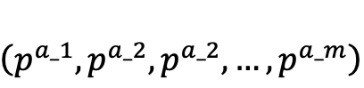
这样,动作空间就可以表示为, 图示如下(引自 Fan, 19)。
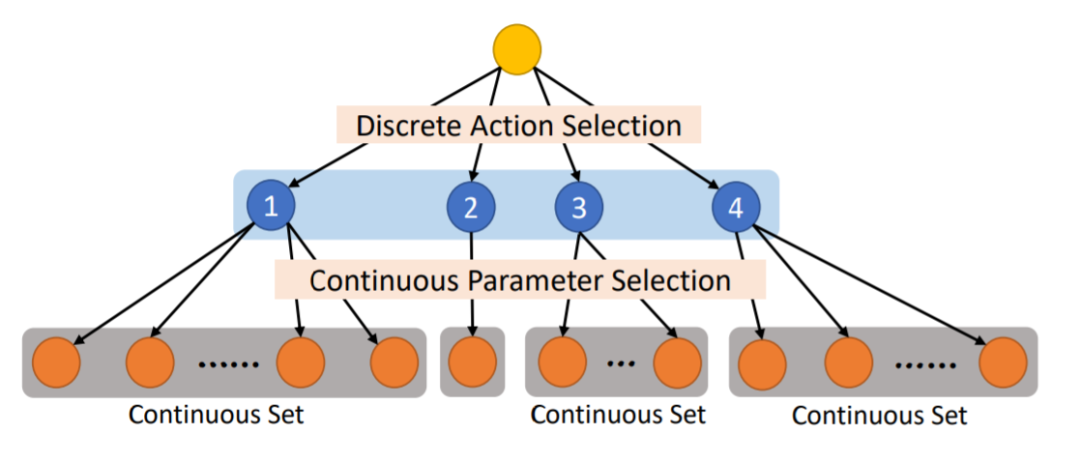
Parameterized Action Space
🪐Hierarchically Structured Action Space:
Hierarchically Structured Action Space 可以理解为依次多层离散选择,类似游戏中的科技树生成,如下图所示(Fan,19)。
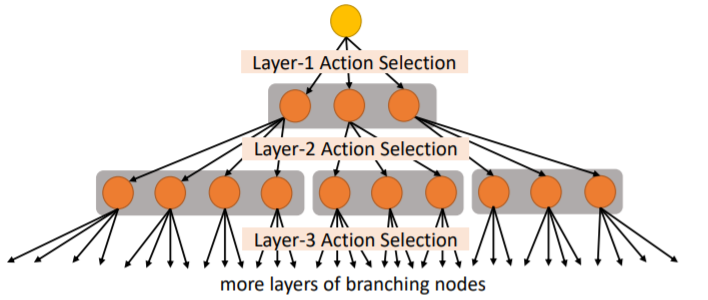
Hierarchically Structured Action Space
🪐Multi-Discrete Action Space:
指多维度的离散动作空间,可以理解为是离散动作空间的n维形式。比如我们每次执行的动作有n个维度,每个维度都由一个离散动作空间构成。
🪐Multi-Binary Action Space:
指多维度的binary动作空间,可以理解为binary空间的n维形式。比如我们每次执行的动作有n个维度,每个维度都由一个0, 1动作空间构成,类比 one-hot encoding。其实就是 Multi-Discrete Action Space 的一种特殊形式。
例如,Slime Volleyball 环境就是multi-binary action space类型,其详细指南可查阅我们的官方环境文档。
✨详细指南链接:
https://di-engine-docs.readthedocs.io/zh_CN/latest/env_tutorial/slime_volleyball_zh.html

Slime Volleyball 环境

在强化学习混合动作空间中,有几个比较经典的环境,例如 Gym-hybrid, Gym-soccer, GoBigger,它们的动作空间类型主要属于我们上述提到的 Parameterized Action Space。
下面我们来分别介绍其环境目标、动作空间、状态空间、奖励空间、终止条件。
🪐gym_hybrid:
✨DI-engine gym_hybrid 环境介绍:
https://di-engine-docs.readthedocs.io/zh_CN/latest/env_tutorial/gym_hybrid_zh.html
环境目标
在gym-hybrid环境中, agent的任务很简单:在边长为2的正方形框内加速(Accelerate)、转向(Turn)或刹车(Break),以停留在红色目标区域。目标区域是一个半径为0.1的圆。如下图所示。

gym-hybrid环境
动作空间
Gym-hybrid 的混合动作空间属于Parameterized Action Space,有3个离散动作:Accelerate,Turn,Break,其中动作Accelerate,Turn需要给出对应的1维连续参数。
- Accelerate (Acceleration value): 表示让agent加速,加速大小由 Acceleration value控制,其取值范围是[0,1]。数值类型为float32。
- Turn (Rotation value): 表示让agent转身,转身方向由Rotation value控制,其取值范围是[-1,1]。数值类型为float32。
- Break (): 表示让agent停止。
状态空间
Gym-hybrid 的状态空间由一个10元素大小的list表示,描述了当前agent的状态。该list包含agent当前的坐标,速度,朝向角度的正余弦值,目标的坐标,agent距离目标的距离,与目标距离相关的bool值,当前相对步数。

奖励空间
每一步的奖励设置为,agent上一个step执行动作后距离目标的长度 减去 当前step执行动作后距离目标的长度,即dist_t-1 - dist_t。算法内置了一个penalty来激励agent更快达到目标。
当episode结束时,如果agent在目标区域停下来,就会获得额外的reward,值为1;如果agent出界或是超过episode最大step次数,则不会获得额外奖励。
用公式表示当前时刻的reward如下:

终止条件
Gym-hybrid 环境每个episode的终止条件是遇到以下任何一种情况:
- agent 成功进入目标区域
- agant 出界
- 达到episode的最大step
🪐Gym-soccer (HFO):
✨【DI-engine】gym_soccer 环境介绍:
https://di-engine-docs.readthedocs.io/zh_CN/latest/env_tutorial/gym_soccer_zh.html
环境目标
HFO (Half-field Offense, 半场进攻) 是机器人世界杯2D足球比赛中的一个子任务。
DI-engine 中的 Gym-Soccer 环境是HFO的简化版本,用来验证应用于混合动作空间的RL算法的性能。如下图所示, 白色小圆点即足球,黄黑色圆圈是进攻球员,紫黑色圆圈是守门员。进攻球员的目标是在守门员的防守下完成射门。
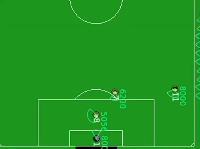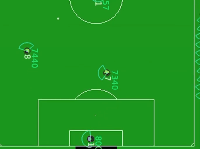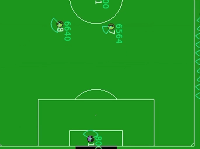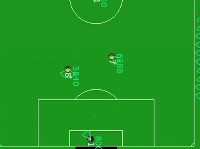
Gym-Soccer 环境
动作空间
Gym-Soccer 的混合动作空间属于Parameterized Action Space,有3个离散动作,每个离散动作有n个连续参数。
-TURN (degree): 表示让agent朝degree方向转身。degree的取值范围是 [-180,180]。当 degree = 0时,表示正前方向;当 degree = 90时,表示正右方向。
-DASH (power, degree): 表示让agent以power 大小的力气向 degree方向移动。degree的取值范围是[-180,180]。power的取值范围是[0,100]。注意:DASH并不会TURN智能体。
-KICK (power, degree): 表示让agent以power 大小的力气向degree方向击球。当agent手里没球时,动作不生效。
使用gym环境空间定义则可表示为:

状态空间
Gym-Soccer 的状态空间描述了当前游戏的状态,分为High Level Feature Set和 Low Level Feature Set,包含agent当前的坐标,球的坐标,agent的朝向等等。数值型的feature被统一scale到[-1,1]的范围。
具体请查阅【官方手册】中的 State Spaces 章节。
✨官方手册:
https://github.com/LARG/HFO/blob/master/doc/manual.pdf
🪐GoBigger:
✨GoBigger环境介绍:
https://gobigger.readthedocs.io/zh_CN/latest/
✨五分钟教你在Go-Bigger环境中设计自己的游戏AI智能体
另外,OpenDILab(开源决策智能平台)在2021年11月举办了全球首届“AI 球球大作战:Go-Bigger多智能体决策智能挑战赛”,欢迎大家关注!
环境目标
Go-Bigger是 OpenDILab 开源了一款多智能体对抗竞技游戏环境。同时,Go-Bigger 还可作为强化学习环境协助多智能体决策 AI 研究。
✨Go-Bigger Github链接:
https://github.com/opendilab/GoBigger
与风靡全球的Agar(https://agar.io/) 等游戏类似,在 Go-Bigger 中,玩家(AI)控制地图中的一个或多个圆形球,通过吃食物球和其他比玩家球小的单位来尽可能获得更多重量,并需避免被更大的球吃掉。
每个玩家开始仅有一个球,当球达到足够大时,玩家可使其分裂、吐孢子或融合,和同伴完美配合来输出博弈策略,并通过AI技术来操控智能体由小到大地进化,凭借对团队中多智能体的策略控制来吃掉尽可能多的敌人,从而让己方变得更强大并获得最终胜利。
动作空间
GoBigger 的动作空间是比较简单的。玩家操控的每个球只能进行移动,吐孢子,分裂,停止。其动作空间表示如下:

- x, y: 是单位圆中的一个点 (x, y),用来代表玩家对球的加速度的操控。
GoBigger 会对加速度进行归一化,保证其的模长不会超过 1。如果用户不提供加速度变化,可以提供 (None, None) 表示不对移动进行改变。
- action_type: Int
- -1代表无动作,意味着继续维持上一帧的速度0 代表在给定方向上吐孢子。如果方向无指定,则在移动方向上执行。并修改移动方向为给定方向。
- 1代表在给定方向上进行分裂。如果方向无指定,则在移动方向上执行。并修改移动方向为给定方向。
- 2代表停止运动并将所有的分身球聚集起来。
- 3代表在给定方向上吐孢子。如果方向无指定,则在移动方向上执行。不修改移动方向。
- 4代表在给定方向上进行分裂。如果方向无指定,则在移动方向上执行。不修改移动方向。
状态空间
状态空间部分所含信息较多,主要是用来描述当前的游戏状态。具体可以参考上述官方文档链接。
奖励空间
Go-Bigger是一项关于比谁的队伍更大的对抗游戏,因此奖励函数的定义也非常简单,即相邻两帧整个队伍的大小之差。
如下图所示两张表示相邻两个动作帧,右侧计分板显示各个队伍实时的大小数值,将当前帧的大小减去上一帧的大小,就定义得到了奖励值。而对于整场比赛,则使用每一步奖励的累加和作为最终的评价值。评价值最大的队伍,将赢得本局比赛。
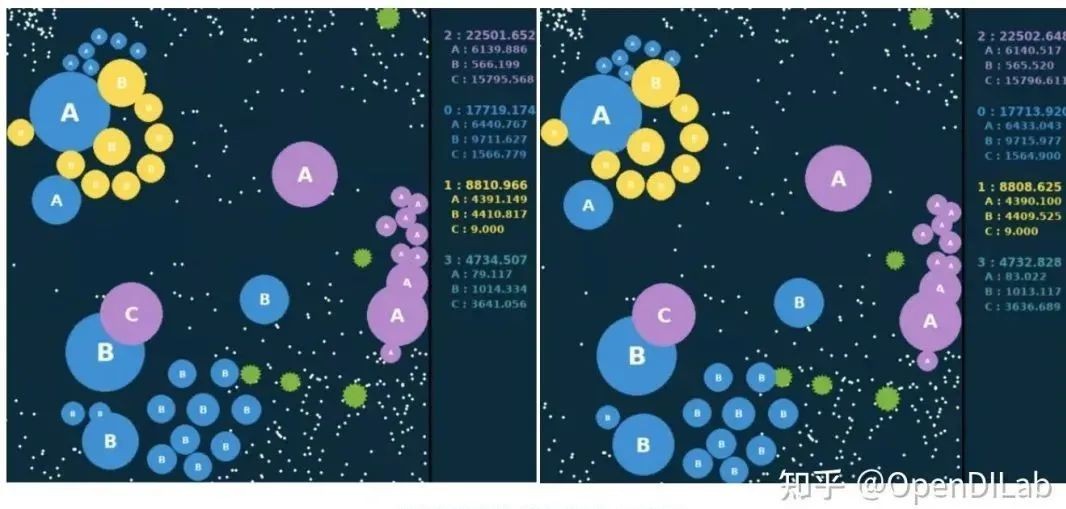
Go-Bigger环境奖励的帧间变化示意图
终止条件
并无真正意义上的终止条件,只是通过限制游戏时间的长短来控制终止状态。
参考文献
[1] Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space. IJCAI 2019: 2279-2285.


扫码即可了解更多开源信息~