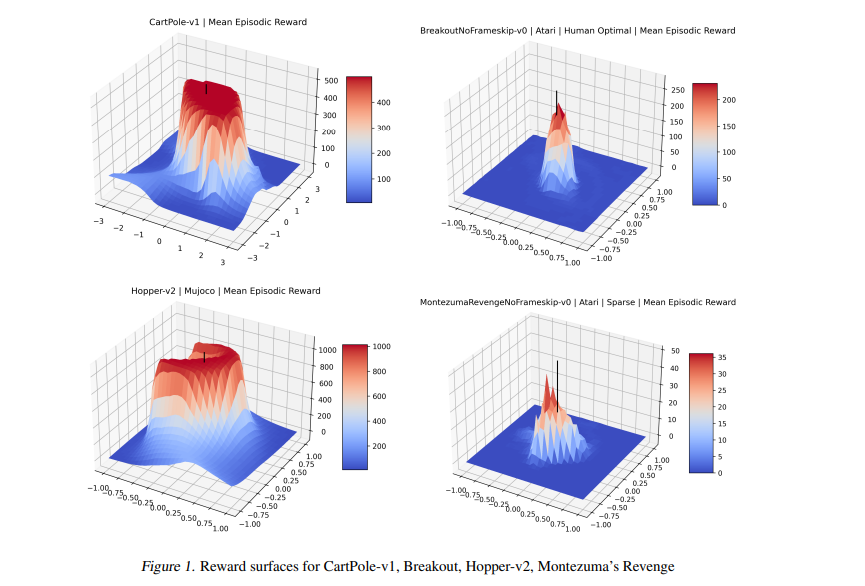
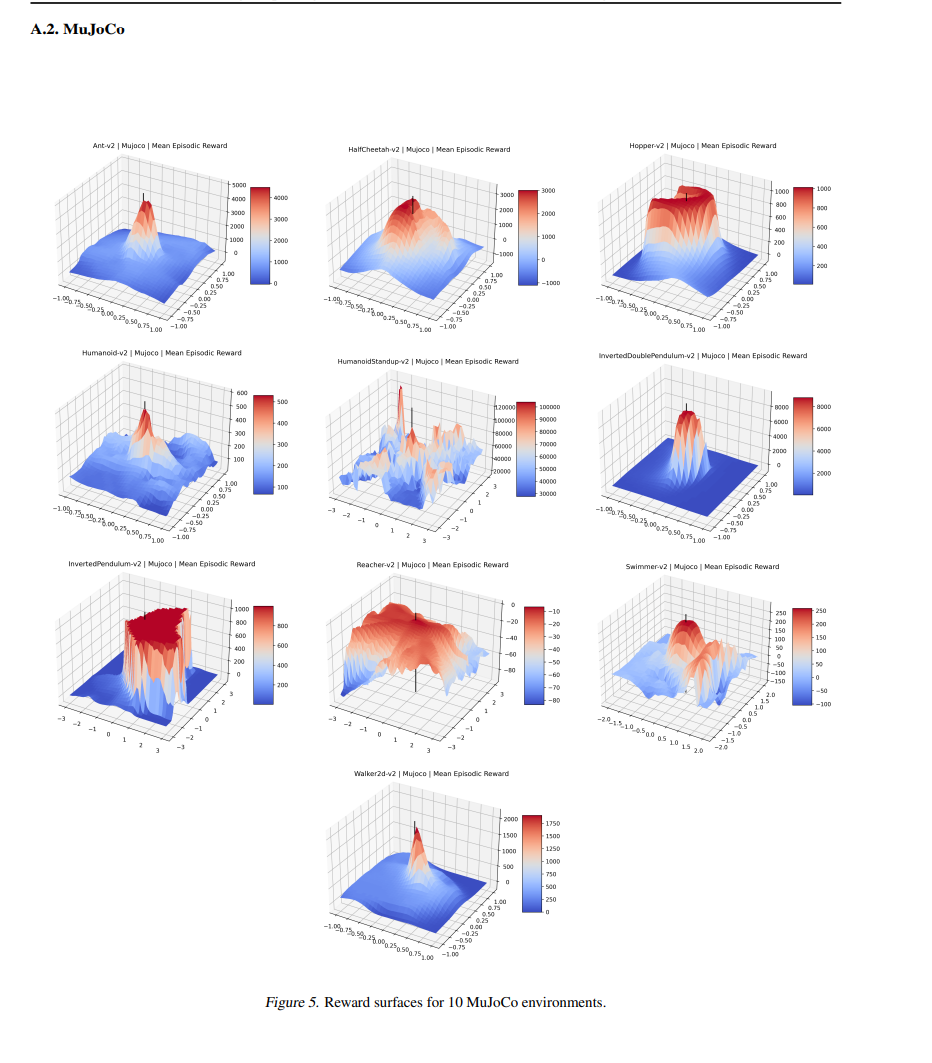
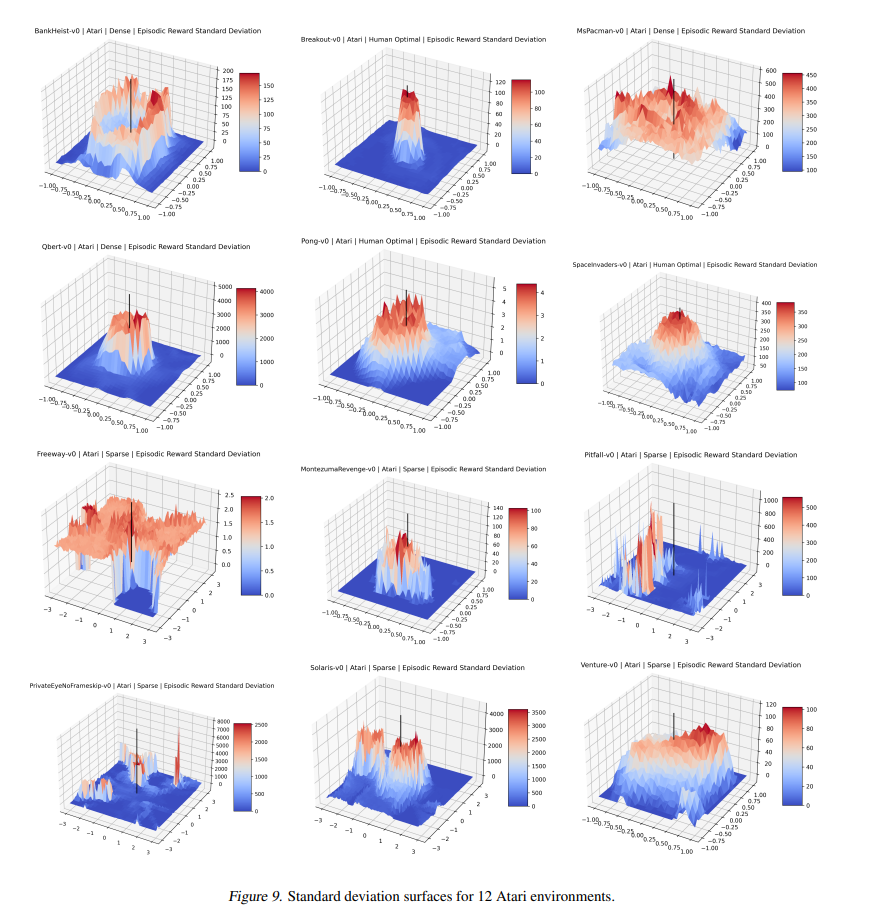
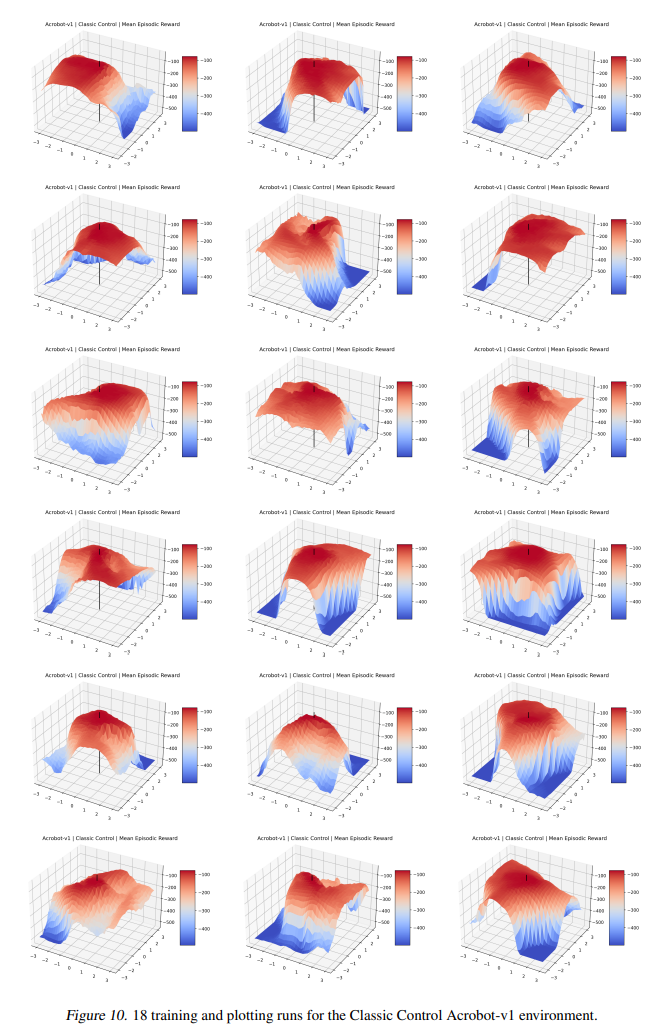
可视化优化景观导致了许多关于数值优化的基本见解,以及对优化技术的新颖改进。然而,强化学习优化的目标(“奖励表面”)的可视化仅针对少数狭窄的上下文生成。这项工作首次展示了 Gym 中 27 个最广泛使用的强化学习环境的奖励表面和相关可视化。我们还探索了策略梯度方向的奖励表面,并首次表明许多流行的强化学习环境经常出现“悬崖”(预期回报突然大幅下降)。我们证明了 A2C 经常“跳出”这些悬崖进入参数空间的低奖励区域,而 PPO 则避开它们,这证实了 PPO 比以前的方法提高性能的流行直觉。我们还引入了一个高度可扩展的库,允许研究人员在未来轻松生成这些可视化。我们的发现为解释现代强化学习方法的成功和失败提供了新的直觉,我们的可视化以新颖的方式具体描述了强化学习代理的几种失败模式。
Visualizing optimization landscapes has led to many fundamental insights in numeric optimization, and novel improvements to optimization techniques. However, visualizations of the objective that reinforcement learning optimizes (the “reward surface”) have only ever been generated for a small number of narrow contexts. This work presents reward surfaces and related visualizations of 27 of the most widely used reinforcement learning environments in Gym for the first time. We also explore reward surfaces in the policy gradient direction and show for the first time that many popular reinforcement learning environments have frequent “cliffs” (sudden large drops in expected return). We demonstrate that A2C often “dives off” these cliffs into low reward regions of the parameter space while PPO avoids them, confirming a popular intuition for PPO’s improved performance over previous methods. We additionally introduce a highly extensible library that allows researchers to easily generate these visualizations in the future. Our findings provide new intuition to explain the successes and failures of modern RL methods, and our visualizations concretely characterize several failure modes of reinforcement learning agents in novel ways.
pdf: https://arxiv.org/pdf/2205.07015v2.pdf