paper: https://arxiv.org/abs/2006.09359
Blog: https://bair.berkeley.edu/blog/2020/09/10/awac/
Live: https://slideslive.com/38941335/accelerating-online-reinforcement-learning-with-offline-datasets
经典强化学习方法需要针对每种行为进行主动探索过程,因此很难在现实环境中应用。如果相反,我们可以让强化学习有效地使用以前收集的数据来辅助在线学习过程,而在线学习过程中的数据可以是专家演示或更普遍的任何先前经验,那么我们可以使强化学习成为实质上更实用的工具。尽管最近有许多方法试图从先前收集的数据中脱机学习,但是使用脱机数据训练策略并通过在线强化学习进一步完善策略仍然异常困难。在本文中,作者系统地分析了为什么这个问题如此具有挑战性,并提出了一种新颖的算法,该算法结合了样本有效的动态编程和最大可能性的策略更新,提供了一种简单有效的框架,能够利用大量离线数据,然后快速进行强化学习政策的在线微调。我们证明了我们的方法能够通过一系列困难的灵巧操作和基准测试任务,结合先前的演示数据和在线经验,快速学习技能。
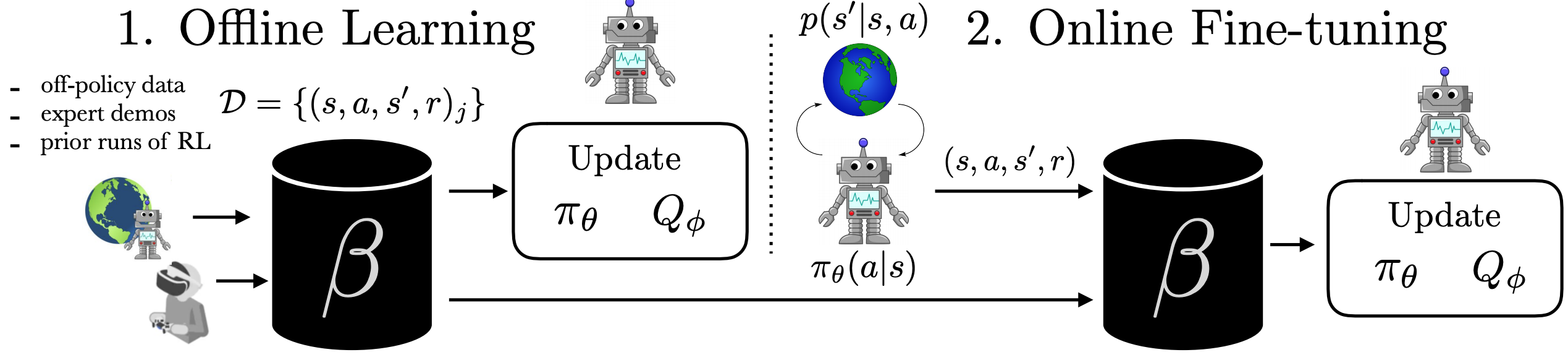
Robots trained with reinforcement learning (RL) have the potential to be used across a huge variety of challenging real world problems. To apply RL to a new problem, you typically set up the environment, define a reward function, and train the robot to solve the task by allowing it to explore the new environment from scratch. While this may eventually work, these “online” RL methods are data hungry and repeating this data inefficient process for every new problem makes it difficult to apply online RL to real world robotics problems. What if instead of repeating the data collection and learning process from scratch every time, we were able to reuse data across multiple problems or experiments? By doing so, we could greatly reduce the burden of data collection with every new problem that is encountered. With hundreds to thousands of robot experiments being constantly run, it is of crucial importance to devise an RL paradigm that can effectively use the large amount of already available data while still continuing to improve behavior on new tasks.
The first step towards moving RL towards a data driven paradigm is to consider the general idea of offline (batch) RL. Offline RL considers the problem of learning optimal policies from arbitrary off-policy data, without any further exploration. This is able to eliminate the data collection problem in RL, and incorporate data from arbitrary sources including other robots or teleoperation. However, depending on the quality of available data and the problem being tackled, we will often need to augment offline training with targeted online improvement. This problem setting actually has unique challenges of its own. In this blog post, we discuss how we can move RL from training from scratch with every new problem to a paradigm which is able to reuse prior data effectively, with some offline training followed by online finetuning.