当使用离线强化学习 (ORL) 训练智能体时,可以使用离线策略评估 (OPE) 来选择最佳智能体。然而,OPE 具有挑战性,其估计并不总是准确的。在许多应用程序中,假设与真实环境的交互成本太高而无法训练策略是现实的,但评估一些选定的策略仍然是可行的。如果我们有机会与环境交互,我们可以希望获得更好的估计,同时保持与环境交互的少量预算。例如在机器人技术和语言中。我们将此问题称为主动离线策略选择(active-ops)。要明智地使用有限的交互,采用贝叶斯优化方法,从 OPE 值开始,并通过它们采取的行动对不同策略之间的依赖关系进行建模。在几个环境和不同的 ORL 策略上测试了这种方法。
近年来,强化学习 (RL) 在解决现实生活中的问题方面取得了巨大进展——离线 RL 使其更加实用。我们现在可以从一个预先记录的数据集中训练许多算法,而不是与环境直接交互。然而,当我们评估手头的策略时,我们失去了离线 RL 在数据效率方面的实际优势。
例如,在训练机器人操纵器时,机器人资源通常是有限的,与在线 RL 相比,通过离线 RL 在单个数据集上训练许多策略为我们提供了很大的数据效率优势。评估每个策略是一个昂贵的过程,需要与机器人进行数千次交互。当我们选择最好的算法、超参数和一些训练步骤时,问题很快就会变得棘手。
为了使 RL 更适用于机器人等实际应用,我们建议使用智能评估程序来选择部署策略,称为主动离线策略选择 (A-OPS)。在 A-OPS 中,我们利用预先记录的数据集并允许与真实环境进行有限的交互以提高选择质量。
主动离线策略选择 在给定预先记录的数据集和与环境的有限交互的情况下从一组策略中选择最佳策略。
为了最大限度地减少与真实环境的交互,我们实现了三个关键功能:
Off-policy 策略评估,例如拟合 Q 评估 (FQE),允许我们基于离线数据集对每个策略的性能进行初步猜测。它与许多环境中的地面实况性能良好相关,包括首次应用它的现实世界机器人技术。
FQE 分数与在 sim2real 和离线 RL 设置中训练的策略的基本事实性能非常一致。
策略的回报使用高斯过程联合建模,其中观察包括 FQE 分数和机器人新收集的少量情节回报。在评估一个策略之后,我们获得了关于所有策略的知识,因为它们的分布通过策略对之间的内核相互关联。内核假设,如果策略采取类似的行动——例如将机器人抓手向类似的方向移动——它们往往会有类似的回报。
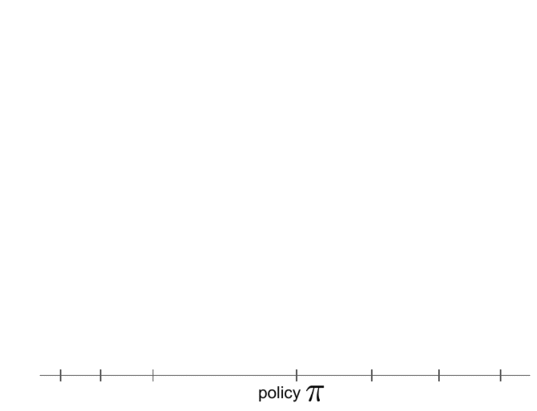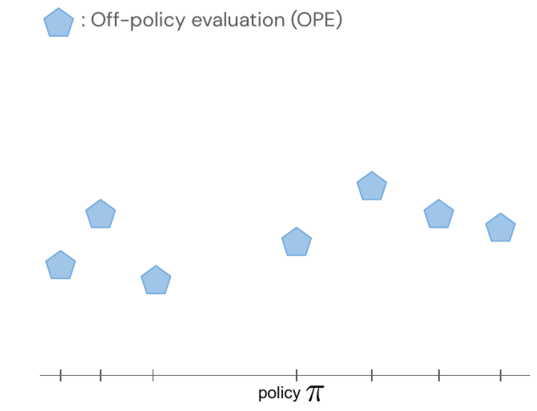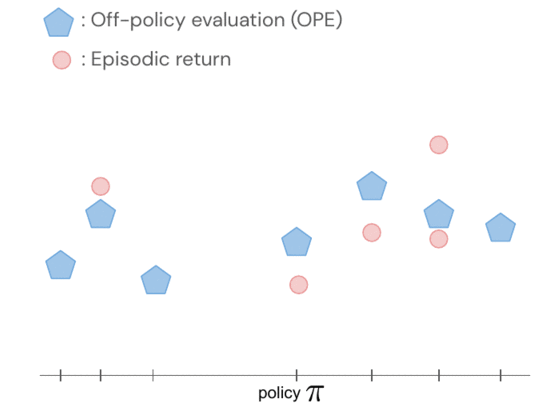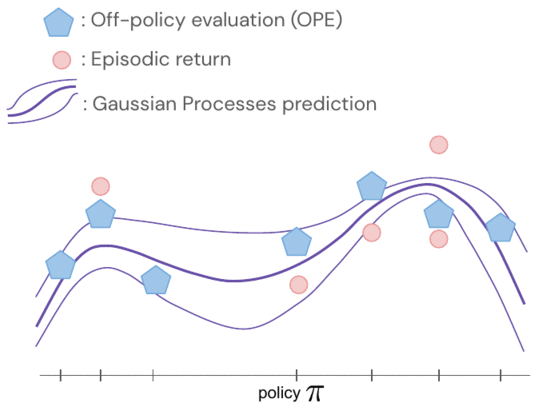
我们使用 OPE 分数和情景回报将潜在策略性能建模为高斯过程。
策略之间的相似性是通过这些政策产生的行动之间的距离来建模的。
为了提高数据效率,我们应用贝叶斯优化并优先考虑接下来要评估的更有希望的策略,即那些具有高预测性能和大方差的策略。
我们在多个领域的多个环境中演示了此过程:dm-control、Atari、模拟和真实机器人。使用 A-OPS 可以迅速减少遗憾,并且通过适度数量的策略评估,我们确定了最佳策略。
在现实世界的机器人实验中,A-OPS 有助于比其他基线更快地识别出非常好的策略。在 20 个保单中找到一个后悔接近零的保单所花费的时间与使用当前程序评估两个保单所花费的时间相同。
PDF链接:https://arxiv.org/pdf/2106.10251.pdf
代码链接:https://github.com/deepmind/active_ops